In diesem Artikel vergleichen wir moderne Modelle für Face Detection und Tracking nach wichtigen Kriterien: Geschwindigkeit, Erkennungsgenauigkeit und einfache Implementierung. Wir analysieren echte Python Code-Beispiele, besprechen Performance-Optimierung und wichtige ethische Aspekte.
Gesichtserkennung ist eine Schlüsseltechnologie, die unzähligen Anwendungen zugrunde liegt: vom Entsperren des Smartphones bis hin zu komplexen Sicherheitssystemen. Heute sind dutzende Modelle auf dem Markt verfügbar, von denen jedes hohe Genauigkeit und Geschwindigkeit verspricht. Aber wie findest du dich in dieser Vielfalt zurecht und wählst das richtige Modell für dein Projekt aus?
Ob es sich um eine mobile App mit Face Detection in Echtzeit oder ein Videoüberwachungssystem mit hohen Genauigkeitsanforderungen handelt - die richtige Modellwahl ist entscheidend. Das Studium von Vergleichstests und Reviews führender Face Detection und Tracking Algorithmen ist der erste Schritt zur effektiven Implementierung der Technologie. Dieser Ansatz hilft nicht nur dabei, Ressourcen zu sparen, sondern auch eine stabile und schnelle Performance in realen Bedingungen zu erreichen.
Einführung in die Technologien
Performance-Landschaft
Moderne Face Detection Modelle lassen sich grob in Performance-Level nach dem Verhältnis von Geschwindigkeit und Genauigkeit unterteilen. Umfassende Tests zeigen, dass führende Algorithmen beeindruckende Ergebnisse erzielen: Sie gewährleisten hohe Verarbeitungsgeschwindigkeit ohne wesentliche Genauigkeitsverluste.
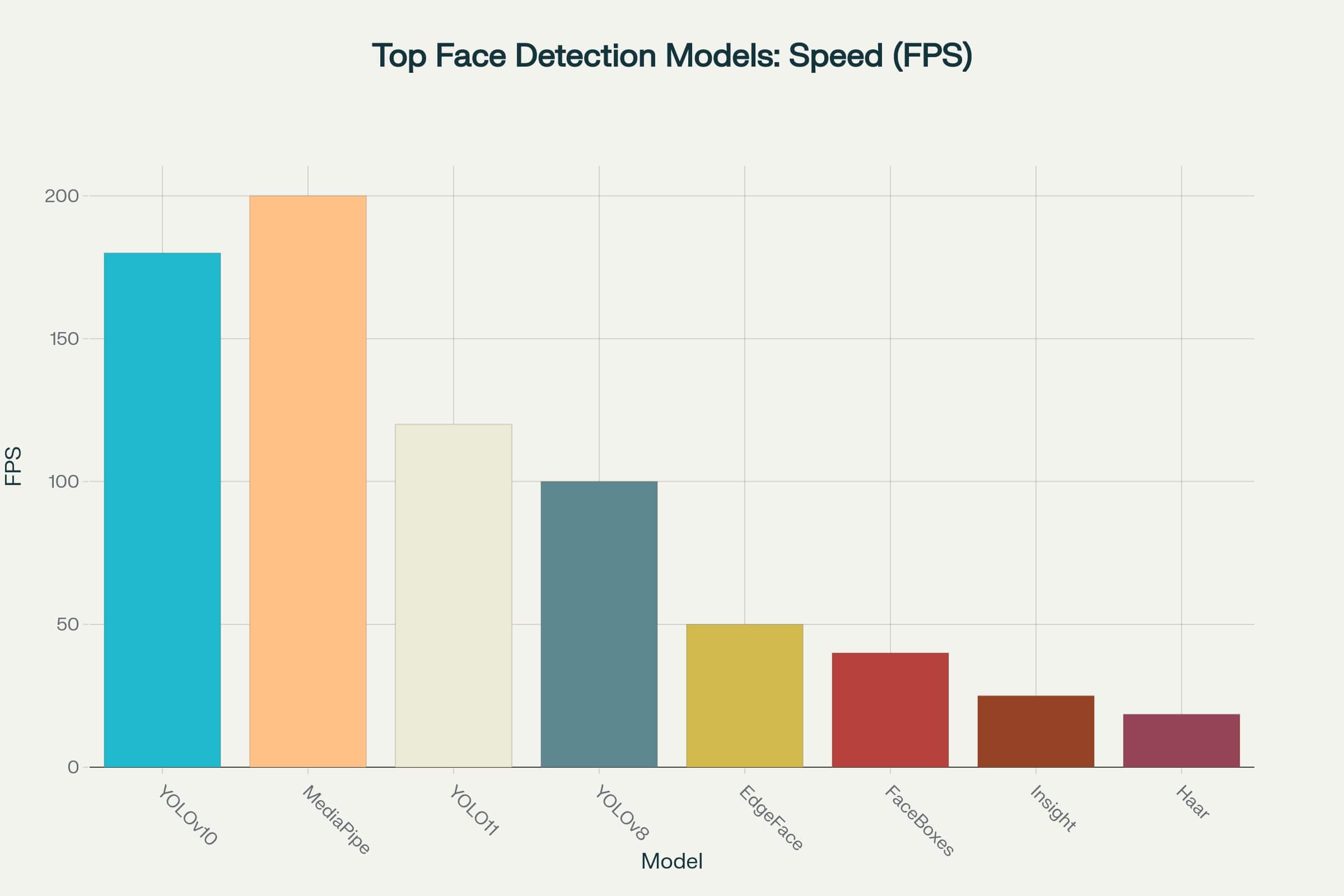
Das eröffnet Möglichkeiten für ihren Einsatz sogar in Anwendungen mit strengen Latenzanforderungen - von mobilen Geräten bis hin zu Edge-Devices in Videoüberwachungssystemen (klicke auf das Bild, um die vergrößerte Version zu öffnen).
Geschwindigkeitsdiagramm der Top Face Detection Modelle
Wenn du dich ausschließlich auf Geschwindigkeit konzentrierst, sehen MediaPipe und YOLOv10 wie unbestrittene Favoriten aus, die 180 bis 200 Frames pro Sekunde verarbeiten. Das macht sie zur ausgezeichneten Wahl für Echtzeit-Aufgaben, wo minimale Latenz wichtig ist.
Jedoch ist hohe Framerate noch nicht alles. Ohne ausreichende Genauigkeit kann selbst das schnellste Modell ineffektiv sein. Zum Beispiel in Videoüberwachungssystemen oder biometrischer Identifikation haben langsamere, aber präzise Modelle immer noch ihre Vorteile.
Modell-Kompromisse
Bei der Analyse des Diagramms der Abhängigkeit von Geschwindigkeit (FPS - Frames Per Second) und Genauigkeit (mAP - mean Average Precision) gruppieren sich die Modelle in deutliche Cluster, die wichtige Kompromisse in der Face Detection widerspiegeln: Erhöhung der Genauigkeit geht oft mit verringerter Geschwindigkeit einher und umgekehrt.
Performance-Diagramm der Top Face Detection Modelle
Dieses Diagramm zeigt vier separate Modell-Kategorien:
Nur CPU (graue Punkte) - solche Modelle wie Haar Cascade und DLib HOG bieten Basis-Performance ohne GPU-Bedarf. Sie zeichnen sich nicht durch hohe Geschwindigkeit aus, eignen sich aber perfekt für Geräte mit begrenzten Ressourcen und eingebettete Systeme.
Leichtgewichte (blaue Punkte) - dazu gehören MediaPipe BlazeFace und verschiedene YOLO-Versionen. Diese Modelle bieten ausgezeichnete Verarbeitungsgeschwindigkeit bei vernünftigem Genauigkeitslevel und sind die optimale Wahl für die meisten Echtzeit-Anwendungen.
Mittlere (orange Punkte) - Modelle wie InsightFace SCRFD und EdgeFace bieten erhöhte Genauigkeit bei moderater Arbeitsgeschwindigkeit. Sie werden gewählt, wenn Genauigkeit wichtig ist, aber dennoch anständige Performance erhalten bleiben soll.
Schwergewichte (rote Punkte) - wie RetinaFace und DSFD. Diese Modelle demonstrieren Forschungsebenen-Genauigkeit, benötigen aber erhebliche Rechenressourcen. Sie sind für kritische Aufgaben bestimmt, wo hohe Hardware-Belastung akzeptabel ist.
Praktische Implementierung
Hier sind einige Python-Code-Beispiele für die Arbeit mit verschiedenen Modellen. Wie du siehst, ist alles gar nicht so kompliziert - die Grundlagen sind ziemlich einfach:
Quick Start mit YOLOv8-Face
YOLOv8 bietet eine ausgezeichnete Balance zwischen Performance und Benutzerfreundlichkeit. Dieses Modell eignet sich perfekt für Anfänger-Entwickler.
fromultralyticsimportYOLOimportcv2# Modell ladenmodel=YOLO('yolov8n-face.pt')# Einzelbild verarbeitenresults=model('path/to/your/image.jpg')# Videostream verarbeitencap=cv2.VideoCapture(0)whileTrue:ret,frame=cap.read()ifnotret:breakresults=model(frame)annotated_frame=results[0].plot()cv2.imshow('Face Detection',annotated_frame)ifcv2.waitKey(1)&0xFF==ord('q'):breakcap.release()cv2.destroyAllWindows()
Mobile Plattform mit MediaPipe
MediaPipe ist für mobile Plattformen optimiert und gewährleistet stabile Performance sogar auf Mittelklasse-Geräten.
importmediapipeasmpimportcv2# MediaPipe Face Detection einmal initialisierenmp_face_detection=mp.solutions.face_detectionmp_drawing=mp.solutions.drawing_utilscap=cv2.VideoCapture(0)# 'with' Operator außerhalb der Schleife für korrektes Ressourcen-Managementwithmp_face_detection.FaceDetection(model_selection=0,min_detection_confidence=0.5)asface_detection:whilecap.isOpened():success,image=cap.read()ifnotsuccess:print("Ignoriere leeren Frame von der Kamera.")continue# Für bessere Performance optional das Bild als nicht bearbeitbar markieren# für Referenz-Übertragung.image.flags.writeable=Falseimage=cv2.cvtColor(image,cv2.COLOR_BGR2RGB)results=face_detection.process(image)# Face Detection Annotationen auf das Bild zeichnen.image.flags.writeable=Trueimage=cv2.cvtColor(image,cv2.COLOR_RGB2BGR)ifresults.detections:fordetectioninresults.detections:mp_drawing.draw_detection(image,detection)cv2.imshow('MediaPipe Face Detection',image)ifcv2.waitKey(5)&0xFF==27:# ESC keybreakcap.release()cv2.destroyAllWindows()
Erweiterte mit RetinaFace
Für Aufgaben, die maximale Genauigkeit erfordern, bleibt RetinaFace der Goldstandard im Bereich Face Detection.
Face Tracking ist ein Prozess der kontinuierlichen Verfolgung von Gesichtern in Videosequenzen, der weit über einfache einmalige Erkennung hinausgeht. Im Gegensatz zur Detection erfordert Tracking stabile Identifikation von Gesichtern über viele Frames hinweg, was hohe Anforderungen an die Algorithmus-Performance stellt.
Das Diagramm zeigt einen Vergleich beliebter Tracking-Modelle nach zwei Schlüsselmetriken:
Verarbeitungsgeschwindigkeit (FPS) - Anzahl der Frames pro Sekunde, die die Modell-Geschwindigkeit bestimmt
Genauigkeit (MOTA Score) - integraler Qualitätsindikator für Tracking, der Identifikationsfehler berücksichtigt
Was ist MOTA?
MOTA (Multiple Object Tracking Accuracy) ist eine Schlüsselmetrik zur Bewertung der Qualität von Object Tracking (einschließlich Gesichtern), die drei Hauptfehlertypen berücksichtigt:
False Positives (FP) - Falschalarme (Tracker erkannte nicht existierendes Objekt).
False Negatives (FN) - übersehene Objekte (Tracker fand real existierendes Objekt nicht).
ID Switches (IDs) - Identifikator-Wechsel (Tracker “verwechselte” Objekt-Labels bei Kreuzung oder temporärem Verschwinden).
Berechnungsformel
$$
MOTA = 1 - \frac{\sum (FP + FN + IDs)}{\sum \text{Gesamtzahl der Objekte in jedem Frame}}
$$
Eigenschaften
Wertebereich: von $-\infty$ bis 1 (je näher zu 1, desto besser).
Beispiel: MOTA = 0.85 bedeutet, dass der Tracker in 15% der Fälle Fehler machte.
Integralindikator: vereint alle Haupttracking-Fehler in einer Bewertung.
Kritisch für Videoüberwachung, Verhaltensanalyse und autonome Systeme, wo Identifikationsstabilität wichtig ist.
Unterschied zu anderen Metriken
MOTP (Multiple Object Tracking Precision) - bewertet Objekt-Lokalisierungsgenauigkeit, berücksichtigt aber keine Identifikationsfehler.
IDF1 - konzentriert sich auf Korrektheit der ID-Zuordnung zwischen Frames.
Für dein Diagramm zeigt hohe MOTA bei einem Modell (z.B. FairMOT oder ByteTrack) dessen Zuverlässigkeit in komplexen Szenen (z.B. bei Gesichtsüberlappung oder Lichtänderungen).
Unter den präsentierten Lösungen (Deeperport, FairMOT, ByteTrack und andere) ist eine erhebliche Streuung der Eigenschaften zu beobachten - einige Modelle zeigen hohe Geschwindigkeit auf Kosten der Genauigkeit, während andere präzises Tracking bieten, aber langsamer arbeiten.
Die Wahl des optimalen Modells hängt immer von der konkreten Aufgabe ab: für Echtzeit ist Geschwindigkeit (FPS) kritisch, für analytische Systeme - Genauigkeit (MOTA). Besonderes Interesse wecken Hybrid-Ansätze (z.B. FaceTracker difu), die versuchen, eine Balance zwischen diesen widersprüchlichen Anforderungen zu finden.
Vergleich der Top Face Detection Modelle
ByteTrack zeigt die beste Balance aus Geschwindigkeit und Genauigkeit: bei rekordverdächtigen 171 FPS behält es einen hohen MOTA-Score. Das macht es zur optimalen Wahl für Echtzeitsysteme, wo sowohl Geschwindigkeit als auch Objekt-Identifikationsstabilität kritisch sind.
ByteTrack für Video
importcv2fromyolox.tracker.byte_trackerimportBYTETrackerfromultralyticsimportYOLOclassVideoTracker:def__init__(self):self.model=YOLO('yolov8n-face.pt')self.tracker=BYTETracker(frame_rate=30)deftrack_video(self,video_path):cap=cv2.VideoCapture(video_path)frame_id=0whileTrue:ret,frame=cap.read()ifnotret:break# Detectionresults=self.model(frame)# In Format für Tracking konvertierendetections=[]iflen(results[0].boxes)>0:boxes=results[0].boxes.xyxy.cpu().numpy()scores=results[0].boxes.conf.cpu().numpy()forbox,scoreinzip(boxes,scores):detections.append([*box,score])# Tracker aktualisierentracks=self.tracker.update(np.array(detections),frame.shape[:2],frame.shape[:2])# Tracks zeichnenfortrackintracks:x1,y1,x2,y2,track_id=track[:5]cv2.rectangle(frame,(int(x1),int(y1)),(int(x2),int(y2)),(0,255,0),2)cv2.putText(frame,f'ID: {int(track_id)}',(int(x1),int(y1)-10),cv2.FONT_HERSHEY_SIMPLEX,0.6,(0,255,0),2)cv2.imshow('Face Tracking',frame)ifcv2.waitKey(1)&0xFF==ord('q'):breakframe_id+=1cap.release()cv2.destroyAllWindows()# Verwendungtracker=VideoTracker()tracker.track_video('path/to/video.mp4')
Für mobile Anwendungen mit Fokus auf flüssige UX ist Face Recognition Geschwindigkeit kritisch wichtig - hier sind Modelle mit 30-60+ FPS optimal, die auch auf schwächeren Geräten funktionieren.
Warum das wichtig ist?
Ohne Lags: 60 FPS = Verarbeitung jedes Frames in 16 ms (Bildschirmaktualisierungsrate von Smartphones).
Energieeffizienz: Kleine Modelle (z.B. MobileFaceNet) sparen Akku.
Offline-Betrieb: Lokale Ausführung ohne Server-Latenz.
Hardware-Optimierung: NPU/GPU des Telefons nutzen (z.B. CoreML auf iOS, NNAPI auf Android).
Caching: Vorhersagbare Szenarien (z.B. Wiedererkennung desselben Gesichts) beschleunigen die Arbeit.
Beispiel: Snapchat Filter funktionieren in Echtzeit dank solcher Optimierungen. Die Wahl eines Modells mit guter Balance aus Geschwindigkeit/Genauigkeit ist einer der Schlüsselfaktoren für mobile App-Erfolg.
# Face Detector Implementierung für mobile Geräte.importmediapipeasmpimportcv2importnumpyasnpimporttimeclassMobileFaceDetector:"""
Klasse für Face Detection im Videostream, optimiert für
Performance auf mobilen Geräten.
Beinhaltet Frame-Skipping für Ziel-FPS und glatte
Rahmen-Darstellung zur Vermeidung von "Flimmern".
"""def__init__(self,model_selection=0,min_detection_confidence=0.7):"""
Initialisiert den Face Detector.
Args:
model_selection (int): Modellwahl. 0 für Nahbereich (bis 2 Meter),
1 für Fernbereich (bis 5 Meter).
min_detection_confidence (float): Minimaler Konfidenzschwellwert für Detection.
"""# --- MediaPipe Face Detection Initialisierung ---# Erstelle Instanz mit gegebenen Parametern.self.face_detection=mp.solutions.face_detection.FaceDetection(model_selection=model_selection,min_detection_confidence=min_detection_confidence,)# --- Variablen für Darstellung und FPS ---# Speichere letzte erfolgreiche Detections, um sie auf übersprungenen Frames zu zeichnen.self.last_results=None# Speichere ursprüngliche Frame-Größe für korrekte Skalierung.self.original_width=0self.original_height=0def_draw_detections(self,frame,detections):"""
Hilfsfunktion zum Zeichnen von Rahmen auf dem Frame.
Args:
frame (np.ndarray): Frame, auf dem gezeichnet werden soll.
detections: Detection-Ergebnisse von MediaPipe.
"""ifdetections:fordetectionindetections:# Relative Rahmen-Koordinaten erhalten (von 0.0 bis 1.0).bboxC=detection.location_data.relative_bounding_box# Koordinaten zurück zur ursprünglichen Frame-Größe skalieren.x=int(bboxC.xmin*self.original_width)y=int(bboxC.ymin*self.original_height)width=int(bboxC.width*self.original_width)height=int(bboxC.height*self.original_height)# Rechteck auf originalem Frame zeichnen.cv2.rectangle(frame,(x,y),(x+width,y+height),(0,255,0),2)returnframedefprocess_frame(self,frame,target_width=320):"""
Verarbeitet einen Frame aus dem Videostream.
Args:
frame (np.ndarray): Eingabe-Frame im BGR-Format.
target_width (int): Zielbreite für Verarbeitung. Frame wird
proportional auf diese Breite verkleinert.
Returns:
np.ndarray: Frame mit gezeichneten Rahmen.
"""self.original_height,self.original_width=frame.shape[:2]# --- Optimierung 1: Auflösungsreduzierung ---# Seitenverhältnis beibehalten.scale=target_width/self.original_widthsmall_frame=cv2.resize(frame,(0,0),fx=scale,fy=scale,interpolation=cv2.INTER_AREA)# --- Optimierung 2: Farbkonvertierung und Performance-Steigerung ---# MediaPipe benötigt RGB. Konvertiere einmal.rgb_small_frame=cv2.cvtColor(small_frame,cv2.COLOR_BGR2RGB)# Markiere Frame als "nur lesen" zur Beschleunigung.rgb_small_frame.flags.writeable=False# --- Face Detection ---results=self.face_detection.process(rgb_small_frame)# Stelle Flag wieder her, falls weitere Arbeit mit Frame nötig.rgb_small_frame.flags.writeable=True# --- Darstellung ---# Wenn Detection erfolgreich war, speichere Ergebnisse.ifresults.detections:self.last_results=results.detections# Zeichne Rahmen auf ursprünglichem Frame. Wenn im aktuellen Frame keine Gesichter# gefunden wurden, aber sie in vorherigen waren, nutze alte Daten für Glätte.processed_frame=self._draw_detections(frame,self.last_results)returnprocessed_framedefclose(self):"""Gibt MediaPipe-Ressourcen frei."""self.face_detection.close()# --- Beispielverwendung mit Webcam ---if__name__=='__main__':# Detector initialisierendetector=MobileFaceDetector(min_detection_confidence=0.5)# Video von Webcam erfassen (0 - meist integrierte Kamera)cap=cv2.VideoCapture(0)ifnotcap.isOpened():print("Fehler: Konnte Webcam nicht öffnen.")exit()# Variablen für FPS-Berechnungprev_frame_time=0new_frame_time=0try:whileTrue:# Frame von Kamera lesensuccess,frame=cap.read()ifnotsuccess:print("Konnte Frame nicht erhalten. Beende.")break# Frame für "Spiegel"-Effekt umdrehenframe=cv2.flip(frame,1)# --- Verarbeitung für Ziel-FPS überspringen ---# Das ist weniger wichtig mit neuer Darstellungslogik, spart aber trotzdem Ressourcen# Hier kannst du deine Frame-Skip-Logik implementieren, falls nötig# Frame verarbeitenprocessed_frame=detector.process_frame(frame)# --- FPS-Berechnung und -Anzeige ---new_frame_time=time.time()fps=1/(new_frame_time-prev_frame_time)prev_frame_time=new_frame_timecv2.putText(processed_frame,f'FPS: {int(fps)}',(10,30),cv2.FONT_HERSHEY_SIMPLEX,1,(0,255,0),2)# Ergebnis anzeigencv2.imshow('Mobile Face Detection',processed_frame)# Beenden mit 'q'-Tasteifcv2.waitKey(1)&0xFF==ord('q'):breakfinally:# Ressourcen freigebenprint("Gebe Ressourcen frei...")cap.release()detector.close()cv2.destroyAllWindows()
Empfohlener Stack:
Für Detection:
MediaPipe Face Detection (BlazeFace) - optimal für Mobile
Für Tracking:
MediaPipe Face Mesh (468 Punkte) - wenn Landmarks benötigt werden
Lightweight OpenPose - für vereinfachtes Tracking
Performance:
60-100 FPS auf durchschnittlichem Smartphone (Snapdragon 7xx)
Bis 200 FPS auf Flaggschiffen (Snapdragon 8 Gen 2/Apple A15+)
Speicher:
Minimum 2GB RAM für Basisfunktionalität
3-4GB+ für komplexe Szenarien (gleichzeitige Detection+Tracking)
Optimierung:
TFLite mit Hardware-Beschleunigung (GPU/NPU)
Ergebnis-Caching für statische Szenen
Dynamische Qualitätsreduzierung bei Geräte-Überhitzung
Sicherheitssysteme
Sicherheitsanwendungen erfordern maximale Genauigkeit mit akzeptabler Latenz:
# Sicherheitssystem mit Tracking, Verifikation,# optimierter Erkennung und Visualisierung.importcv2importnumpyasnpimporttimeimportosimportpicklefromtypingimportDict,List,Any,Optional,Tuple# --- Angenommen, diese Bibliotheken sind installiert ---# pip install opencv-python numpy# pip install insightface# pip install retinaface-pytorch deep-sort-realtime## Wichtig: InsightFace benötigt onnxruntime-gpu. DeepSort hat auch seine Abhängigkeiten.# Installation kann zusätzliche Schritte erfordern, einschließlich Modell-Downloads.fromretinafaceimportRetinaFacefromdeep_sort_realtime.deepsort_trackerimportDeepSortfrominsightface.appimportFaceAnalysisclassAdvancedSecuritySystem:"""
Umfassendes Sicherheitssystem, das Face Detection, Tracking und
Gesichtserkennung mit Echtzeit-Optimierungen vereint.
"""def__init__(self,db_path:str,detection_thresh:float=0.9,recognition_thresh:float=0.5):"""
Initialisierung aller System-Komponenten.
Args:
db_path (str): Pfad zur Gesichtsdatenbank-Datei (.pkl).
detection_thresh (float): Konfidenzschwelle für Face Detector.
recognition_thresh (float): Ähnlichkeitsschwelle für Gesichtserkennung.
"""print("Initialisiere Sicherheitssystem...")# --- Face Detector (RetinaFace) ---# RetinaFace eignet sich gut für "schwierige" Gesichter.# Für CPU kann 'mobilenet' verwendet werden, für GPU - 'resnet50'.self.detector=RetinaFace(gpu_id=0)# -1 für CPU angebenprint("Face Detector (RetinaFace) initialisiert.")# --- Tracker (DeepSort) ---# max_age: wie viele Frames ein Track ohne Detection existieren kann.# n_init: wie oft ein Objekt detektiert werden muss für Track-Start.self.tracker=DeepSort(max_age=30,n_init=3)print("Tracker (DeepSort) initialisiert.")# --- Face Recognition (InsightFace) ---# CUDA für maximale Performance nutzen.self.recognizer=FaceAnalysis(name='buffalo_l',providers=['CUDAExecutionProvider'])self.recognizer.prepare(ctx_id=0)# ctx_id=0 für GPU, -1 für CPUprint("Face Recognition (InsightFace) initialisiert.")# --- Parameter und Datenbank ---self.detection_thresh=detection_threshself.recognition_thresh=recognition_threshself.face_db=self._load_face_database(db_path)# Dictionary für bereits erkannte Identitäten nach track_id# {track_id: {"identity": "Name", "verified": True/False}}self.tracked_identities:Dict[str,Dict[str,Any]]={}def_load_face_database(self,db_path:str)->Optional[Dict[str,np.ndarray]]:"""Lädt vorab erstellte Embedding-Datenbank."""ifnotos.path.exists(db_path):print(f"Fehler: Datenbankdatei nicht gefunden unter: {db_path}")print("Bitte erstelle zuerst eine Datenbank mit create_database_from_folder().")returnNonewithopen(db_path,'rb')asf:db=pickle.load(f)print(f"Gesichtsdatenbank erfolgreich geladen. {len(db)} Identitäten gefunden.")returndbdef_extract_embedding(self,frame:np.ndarray,bbox:np.ndarray)->Optional[np.ndarray]:"""Extrahiert Embedding (Feature-Vektor) aus Gesichtsbereich."""# Gesicht sicher ausschneiden, Koordinaten an Frame-Grenzen beschneidenh,w=frame.shape[:2]x1,y1,x2,y2=np.maximum(0,bbox).astype(int)x2,y2=min(x2,w),min(y2,h)face_img=frame[y1:y2,x1:x2]ifface_img.size==0:returnNone# InsightFace für Embedding verwendenfaces=self.recognizer.get(face_img)returnfaces[0].embeddingiffaceselseNonedef_find_match(self,embedding:np.ndarray)->Tuple[str,float]:"""Findet ähnlichstes Gesicht in der Datenbank."""ifembeddingisNoneorself.face_dbisNone:return"Unknown",0.0best_match="Unknown"best_score=0.0# Kosinus-Ähnlichkeit verwenden (Skalarprodukt normalisierter Vektoren)forname,db_embedinself.face_db.items():score=np.dot(embedding,db_embed)/(np.linalg.norm(embedding)*np.linalg.norm(db_embed))ifscore>self.recognition_threshandscore>best_score:best_score=scorebest_match=namereturnbest_match,best_scoredefprocess_frame(self,frame:np.ndarray)->np.ndarray:"""
Vollständiger Verarbeitungszyklus eines Frames: Detection, Tracking, Recognition.
Returns:
np.ndarray: Frame mit gezeichneten Informationen (Rahmen, ID, Namen).
"""ifself.face_dbisNone:cv2.putText(frame,"Face DB not loaded!",(20,40),cv2.FONT_HERSHEY_SIMPLEX,1,(0,0,255),2)returnframe# --- 1. Detection ---# RetinaFace gibt Dictionary zurück, das konvertiert werden mussdetections_raw=self.detector.detect(frame,threshold=self.detection_thresh)# Konvertierung in DeepSort-verständliches Format: [[x1, y1, x2, y2], confidence]deepsort_detections=[]forface_dataindetections_raw:x1,y1,x2,y2,conf=face_datadeepsort_detections.append(([x1,y1,x2,y2],conf,"face"))# --- 2. Tracking ---tracks=self.tracker.update_tracks(deepsort_detections,frame=frame)# --- 3. Recognition und Visualisierung ---fortrackintracks:ifnottrack.is_confirmed():continuetrack_id=track.track_idbbox=track.to_tlbr()# (x1, y1, x2, y2)identity_info=self.tracked_identities.get(track_id)# OPTIMIERUNG: Nur neue Tracks erkennenifidentity_infoisNone:embedding=self._extract_embedding(frame,bbox)name,score=self._find_match(embedding)self.tracked_identities[track_id]={"identity":name,"score":score}identity_info=self.tracked_identities[track_id]# --- Visualisierung ---name=identity_info.get("identity","Unknown")score=identity_info.get("score",0.0)color=(0,255,0)ifname!="Unknown"else(0,0,255)# Rahmen zeichnencv2.rectangle(frame,(int(bbox[0]),int(bbox[1])),(int(bbox[2]),int(bbox[3])),color,2)# Text für Beschriftung bildenlabel=f"ID: {track_id} | {name} ({score:.2f})"# Beschriftung zeichnencv2.putText(frame,label,(int(bbox[0]),int(bbox[1])-10),cv2.FONT_HERSHEY_SIMPLEX,0.7,color,2)returnframedefcreate_database_from_folder(self,folder_path:str,output_db_path:str):"""
Erstellt Embedding-Datenbank aus Ordner mit Bildern.
Ordnerstruktur:
- folder_path/
- person_1/
- image1.jpg
- image2.png
- person_2/
- photo.jpg
"""face_db={}print(f"Erstelle Datenbank aus Ordner: {folder_path}")forperson_nameinos.listdir(folder_path):person_folder=os.path.join(folder_path,person_name)ifnotos.path.isdir(person_folder):continueembeddings=[]forimage_nameinos.listdir(person_folder):image_path=os.path.join(person_folder,image_name)img=cv2.imread(image_path)ifimgisNone:continue# Embedding für erstes gefundenes Gesicht im Foto erhaltenfaces=self.recognizer.get(img)iffaces:embeddings.append(faces[0].embedding)ifembeddings:# Embeddings für größere Stabilität mittelnface_db[person_name]=np.mean(embeddings,axis=0)print(f"-> Gesicht gefunden und verarbeitet: {person_name}")# Datenbank in Datei speichernwithopen(output_db_path,'wb')asf:pickle.dump(face_db,f)print(f"Datenbank erfolgreich erstellt und gespeichert unter: {output_db_path}")# --- Beispielverwendung ---if__name__=='__main__':DB_FILE="face_db.pkl"DB_SOURCE_FOLDER="face_images"# Ordner mit Fotos für DB-Erstellung# --- Schritt 1: Datenbank erstellen (einmalig ausführen) ---# Für diesen Schritt muss Ordner face_images erstellt werden mit Unterordnern# mit Personennamen, die deren Fotos enthalten.ifnotos.path.exists(DB_FILE):print("Datenbank nicht gefunden. Starte Erstellungsprozess...")# Temporären Ordner für Beispiel erstellen, falls nicht vorhandenifnotos.path.exists(DB_SOURCE_FOLDER):os.makedirs(os.path.join(DB_SOURCE_FOLDER,"person_example"))print(f"Beispielordner erstellt: {DB_SOURCE_FOLDER}/person_example")print("Bitte lege .jpg-Dateien mit Gesichtern dort ab und starte das Skript neu.")exit()# System nur für DB-Erstellung initialisierentemp_system=AdvancedSecuritySystem(db_path=DB_FILE)temp_system.create_database_from_folder(DB_SOURCE_FOLDER,DB_FILE)print("-"*30)# --- Schritt 2: System im Videostream starten ---system=AdvancedSecuritySystem(db_path=DB_FILE)cap=cv2.VideoCapture(0)# 0 für Webcam oder Pfad zu Videodateiifnotcap.isOpened():print("Fehler: Konnte Videostream nicht öffnen.")exit()prev_time=0try:whileTrue:success,frame=cap.read()ifnotsuccess:break# Frame-Verarbeitungprocessed_frame=system.process_frame(frame)# FPS-Berechnung und -Anzeigecurr_time=time.time()fps=1/(curr_time-prev_time)prev_time=curr_timecv2.putText(processed_frame,f"FPS: {int(fps)}",(20,80),cv2.FONT_HERSHEY_SIMPLEX,1,(0,255,0),2)cv2.imshow("Advanced Security System",processed_frame)ifcv2.waitKey(1)&0xFF==ord('q'):breakfinally:print("Beende und gebe Ressourcen frei.")cap.release()cv2.destroyAllWindows()
Empfohlener Stack:
Für Detection:
RetinaFace (ResNet50) - maximale Genauigkeit für kritische Aufgaben
Asynchrone Pipeline-Verarbeitung für verteilte Systeme
Sicherheit:
Obligatorische Liveness-Prüfung (Anti-Spoofing)
Embedding-Verschlüsselung in der Datenbank
Zeitstempel für Zugriffs-Audit
Edge und IoT
Umgebungen mit begrenzten Ressourcen erfordern sorgfältige Optimierung:
# Face Detection und Tracking Implementierung für Edge-Geräte# mit TensorFlow Lite.importcv2importnumpyasnpimporttimeimportargparsefromtypingimportList,Dict,Any,Tuple,Optional# Für dieses Skript wird tflite_runtime benötigt.# Installation: pip install tflite-runtimetry:fromtflite_runtime.interpreterimportInterpreterexceptImportError:print("Fehler: tflite_runtime nicht gefunden. Bitte installiere es:")print("pip install tflite-runtime")exit()classEdgeFacePipeline:"""
Klasse für Face Detection und Tracking auf Edge-Geräten mit TFLite.
Beinhaltet Hardware-Optimierungen und leichtgewichtigen IOU-Tracker.
"""def__init__(self,model_path:str,device:str='cpu',conf_thresh:float=0.7):"""
Pipeline-Initialisierung.
Args:
model_path (str): Pfad zur .tflite Modelldatei.
device (str): Ausführungsgerät ('cpu' oder 'npu').
conf_thresh (float): Konfidenzschwelle für Face Detection.
"""print(f"Lade TFLite-Modell von: {model_path}")self.interpreter=Interpreter(model_path=model_path)self.interpreter.allocate_tensors()self.input_details=self.interpreter.get_input_details()self.output_details=self.interpreter.get_output_details()# Wichtig: exakte Größen erhalten, die das Modell benötigtself.input_height=self.input_details[0]['shape'][1]self.input_width=self.input_details[0]['shape'][2]self.conf_thresh=conf_threshself.tracked_faces:List[Dict[str,Any]]=[]self.next_track_id=0self.iou_thresh=0.4# IOU-Schwelle für Trackingself._configure_device(device)print(f"Pipeline für Gerät initialisiert: {device}")def_configure_device(self,device:str):"""Wendet hardware-spezifische Optimierungen an."""cv2.setUseOptimized(True)# Einstellungen für Neuroprozessor (NPU)ifdevice=='npu':# Hier könnten NPU-spezifische Delegates sein, z.B. 'libedgetpu.so.1'# self.interpreter = Interpreter(model_path=self.model_path,# experimental_delegates=[load_delegate('libedgetpu.so.1')])self.interpreter.set_num_threads(1)print("NPU-Optimierungen angewandt (vereinfachte Konfiguration).")# CPU-Optimierungenelse:self.interpreter.set_num_threads(4)print("CPU-Optimierungen angewandt (4 Threads).")def_preprocess(self,frame:np.ndarray)->np.ndarray:"""
Frame-Vorbereitung für neuronales Netz: Größenänderung und Normalisierung.
"""# Resize auf exakte Modell-Eingabegröße ---resized_frame=cv2.resize(frame,(self.input_width,self.input_height))# In RGB konvertieren, falls Modell das benötigtrgb_frame=cv2.cvtColor(resized_frame,cv2.COLOR_BGR2RGB)# Normalisierung und Batch-Dimension hinzufügen# Viele TFLite-Modelle erwarten float32 im Bereich [-1, 1] oder [0, 1]# oder uint8 [0, 255]. Prüfe Dokumentation deines Modells.# Hier nehmen wir float32 [0, 1] an.input_data=np.expand_dims(rgb_frame,axis=0).astype(np.float32)/255.0returninput_datadefprocess_frame(self,frame:np.ndarray)->List[Dict[str,Any]]:"""
Vollständiger Verarbeitungszyklus: Detection und Tracking.
Args:
frame (np.ndarray): Eingabe-Frame im BGR-Format.
Returns:
List[Dict[str, Any]]: Liste verfolgter Gesichter mit ID und Koordinaten.
"""original_h,original_w=frame.shape[:2]# 1. Frame-Vorverarbeitunginput_data=self._preprocess(frame)# 2. Modell-Inferenzself.interpreter.set_tensor(self.input_details[0]['index'],input_data)self.interpreter.invoke()# 3. Ergebnisse erhalten und nachverarbeiten# Ausgabeformat kann für verschiedene Modelle unterschiedlich sein.# Nehmen an, dass Modell [boxes, scores] zurückgibt.boxes=self.interpreter.get_tensor(self.output_details[0]['index'])[0]scores=self.interpreter.get_tensor(self.output_details[1]['index'])[0]current_detections=[]fori,scoreinenumerate(scores):ifscore>self.conf_thresh:# Koordinaten werden normalisiert zurückgegeben [ymin, xmin, ymax, xmax]ymin,xmin,ymax,xmax=boxes[i]# Koordinaten auf ursprüngliche Frame-Größe skalierenabs_xmin=int(xmin*original_w)abs_ymin=int(ymin*original_h)abs_xmax=int(xmax*original_w)abs_ymax=int(ymax*original_h)current_detections.append({'bbox':(abs_xmin,abs_ymin,abs_xmax,abs_ymax),'score':float(score)})# 4. Tracker-Updateself._update_tracker(current_detections)returnself.tracked_facesdef_update_tracker(self,new_detections:List[Dict[str,Any]]):"""Aktualisiert Tracks basierend auf neuen Detections mit IOU."""ifnotself.tracked_faces:# Wenn keine Tracks vorhanden, aus neuen Detections initialisierenfordetinnew_detections:det['track_id']=self.next_track_iddet['age']=0# Track-"Alter"-Zählerself.tracked_faces.append(det)self.next_track_id+=1returnmatched_indices=set()# Versuche neue Detections mit existierenden Tracks zu verknüpfenfori,trackinenumerate(self.tracked_faces):best_match_iou=0best_match_idx=-1forj,detinenumerate(new_detections):ifjinmatched_indices:continueiou=self._calculate_iou(track['bbox'],det['bbox'])ifiou>self.iou_threshandiou>best_match_iou:best_match_iou=ioubest_match_idx=jifbest_match_idx!=-1:# Track aktualisierentrack['bbox']=new_detections[best_match_idx]['bbox']track['age']=0# Alter zurücksetzen, da Track gefundenmatched_indices.add(best_match_idx)else:# Alter erhöhen, wenn Track nicht gefundentrack['age']+=1# Neue Tracks für nicht verknüpfte Detections hinzufügenforj,detinenumerate(new_detections):ifjnotinmatched_indices:det['track_id']=self.next_track_iddet['age']=0self.tracked_faces.append(det)self.next_track_id+=1# Alte Tracks entfernen, die eine Zeit lang nicht gesehen wurdenself.tracked_faces=[tfortinself.tracked_facesift['age']<15]@staticmethoddef_calculate_iou(box1:Tuple,box2:Tuple)->float:"""Berechnet Intersection over Union (IOU) für zwei Rahmen."""x1,y1,x2,y2=box1x3,y3,x4,y4=box2xi1,yi1=max(x1,x3),max(y1,y3)xi2,yi2=min(x2,x4),min(y2,y4)inter_area=max(0,xi2-xi1)*max(0,yi2-yi1)box1_area=(x2-x1)*(y2-y1)box2_area=(x4-x3)*(y4-y3)union_area=box1_area+box2_area-inter_areareturninter_area/union_areaifunion_area>0else0.0defdraw_results(frame:np.ndarray,faces:List[Dict[str,Any]]):"""Zeichnet Ergebnisse auf Frame."""forfaceinfaces:# Koordinaten für Darstellung verwendenxmin,ymin,xmax,ymax=face['bbox']track_id=face['track_id']cv2.rectangle(frame,(xmin,ymin),(xmax,ymax),(0,255,0),2)label=f"ID: {track_id}"cv2.putText(frame,label,(xmin,ymin-10),cv2.FONT_HERSHEY_SIMPLEX,0.7,(0,255,0),2)# Beispielverwendungif__name__=="__main__":parser=argparse.ArgumentParser(description="Face Detection auf Edge-Geräten")parser.add_argument("--model",type=str,required=True,help="Pfad zur .tflite Modelldatei.")parser.add_argument("--device",type=str,default='cpu',choices=['cpu','npu'],help="Gerät für Inferenz.")parser.add_argument("--video",type=str,help="Pfad zu Videodatei. Falls nicht angegeben, nutze Webcam.")args=parser.parse_args()pipeline=EdgeFacePipeline(model_path=args.model,device=args.device)cap=cv2.VideoCapture(args.videoifargs.videoelse0)ifnotcap.isOpened():print(f"Fehler: Konnte Videoquelle nicht öffnen.")exit()prev_time=0try:whileTrue:ret,frame=cap.read()ifnotret:break# Frame-Verarbeitungtracked_faces=pipeline.process_frame(frame)# Ergebnisse visualisierendraw_results(frame,tracked_faces)# FPS anzeigencurr_time=time.time()fps=1/(curr_time-prev_time)prev_time=curr_timecv2.putText(frame,f"FPS: {int(fps)}",(10,30),cv2.FONT_HERSHEY_SIMPLEX,1,(0,0,255),2)cv2.imshow('Edge Face Detection',frame)ifcv2.waitKey(1)&0xFF==ord('q'):breakfinally:print("Beende und gebe Ressourcen frei.")cap.release()cv2.destroyAllWindows()
Empfohlener Stack:
Für Detection:
YOLOv10n-face (Nano-Version) – bis 180 FPS auf Raspberry Pi
Haar Cascades – minimale Anforderungen (funktioniert sogar auf ESP32)
MobileNetV3-SSD – Balance aus Genauigkeit und Geschwindigkeit (30–60 FPS)
Für Tracking:
IOU Tracker – ultra-leichtes Tracking (0.1 ms pro Frame)
CSRT – präzises Tracking für statische Kameras
KCF – Kompromiss zwischen Geschwindigkeit und Genauigkeit
Performance:
30–180 FPS je nach Hardware und Modell
1–5 W Energieverbrauch
Speicher:
Minimum 512 MB RAM für Haar Cascades
1–2 GB RAM für YOLOv10n und MobileNet
Optimierung:
TensorFlow Lite für Deployment
INT8-Quantisierung für Beschleunigung
Hardware-Beschleunigung (NPU, GPU)
Dynamische Auflösungsskalierung
Unterstützte Geräte:
Raspberry Pi (3B+/4/5)
Jetson Nano
Orange Pi 5
ESP32-CAM (nur Haar Cascades)
Installation und Setup
Umgebungssetup
Korrekte Entwicklungsumgebung ist kritisch für optimale Performance.
Effizientes Speicher- und Rechenressourcen-Management beeinflusst die System-Performance erheblich.
importgcimporttorchdefoptimize_gpu_memory():"""GPU-Speicher nach Verarbeitung bereinigen"""iftorch.cuda.is_available():torch.cuda.empty_cache()gc.collect()defbatch_processing(image_list,model,batch_size=4):"""Batch-Verarbeitung für Durchsatz-Optimierung"""results=[]foriinrange(0,len(image_list),batch_size):batch=image_list[i:i+batch_size]batch_results=model(batch)results.extend(batch_results)# Speicher nach jedem Batch bereinigenoptimize_gpu_memory()returnresults
Multi-Threading Verarbeitung
Trennung von Frame-Lesen, -Verarbeitung und -Anzeige ermöglicht maximale Nutzung verfügbarer System-Ressourcen.
Face Detection Modelle können Leistungsunterschiede zwischen verschiedenen demografischen Gruppen zeigen. Viele Modelle arbeiten weniger genau (Fehlerrate kann 30% höher sein) bei Detection und Tracking von Gesichtern von Menschen mit dunklerer Hautfarbe, Frauen und älteren Menschen.
Einige Tipps zur Vermeidung solcher Situationen:
Teste verschiedene demografische Gruppen: Bewerte immer die Performance deines gewählten Modells für verschiedene Altersgruppen, Geschlechter und Ethnien mit diversen Test-Datensätzen.
Überwache Real-World Performance: Bewerte kontinuierlich, wie dein System für verschiedene Nutzergruppen in Produktionsumgebungen funktioniert.
Berücksichtige spezialisierte Modelle: Einige Frameworks wie MediaPipe und neue YOLO-Varianten wurden speziell auf vielfältigeren Datensätzen trainiert, um Bias zu reduzieren.
# Beispiel: Bias-Testing Frameworkdefevaluate_model_bias(model,test_datasets):"""
Bewertung der Modell-Performance nach demografischen Gruppen
"""results={}forgroup_name,datasetintest_datasets.items():detections=[]forimage_pathindataset['images']:result=model(image_path)detections.append(result)# Metriken für diese demografische Gruppe berechnenaccuracy=calculate_accuracy(detections,dataset['ground_truth'])results[group_name]={'accuracy':accuracy,'sample_size':len(dataset['images'])}returnresults# Beispielverwendungdemographic_results=evaluate_model_bias(model,{'young':young_adult_dataset,'elderly':elderly_dataset,'diverse':diverse_dataset})
Hinweis: Code-Fragmente in diesem Abschnitt stellen konzeptuelle Frameworks dar. Hilfsfunktionen wie calculate_accuracy, present_consent_dialog oder spezifische UI-Implementierungen müssen basierend auf deinen App-Anforderungen und gewählten Frameworks entwickelt werden.
Datenschutz-Priorität
Die Wahl zwischen lokaler oder Cloud-Datenverarbeitung kann erhebliche Datenschutz-Konsequenzen haben:
Vorteile lokaler Verarbeitung:
Personendaten verlassen nie das Nutzergerät
Reduziertes Risiko von Datenlecks
Compliance mit Anforderungen wie GDPR
Nutzer behält Kontrolle über seine biometrischen Daten
Einverständnis einholen
Face Tracking Technologien werfen auch wichtige Fragen zu Einverständnis und Transparenz auf:
Best Practices für Einverständnis:
Nutzer müssen verstehen, welche Daten gesammelt und wie sie verwendet werden
Biete Opt-out-Optionen für Tracking bei Erhaltung der Kernfunktionalität
Bitte Nutzer regelmäßig, ihr Einverständnis zu bestätigen
Implementierungsbeispiel:
classConsentAwareFaceTracker:def__init__(self):self.user_consent=self.check_user_consent()self.tracking_enabled=Falsedefcheck_user_consent(self):# Gespeicherte Nutzer-Präferenzen prüfen# Einverständnis-Status und Zeitstempel zurückgebenpassdefrequest_consent(self):"""
Klaren Einverständnis-Dialog dem Nutzer präsentieren
"""consent_text="""
Diese App nutzt Face Detection für:
- Verbesserung deiner AR-Filter-Erfahrung
- Automatischen Kamera-Fokus auf Gesichter
Deine Gesichtsdaten:
- Werden vollständig auf deinem Gerät verarbeitet
- Niemals gespeichert oder übertragen
- Können jederzeit in den Einstellungen deaktiviert werden
Stimmst du der Face Detection zu? [Ja/Nein]
"""returnself.present_consent_dialog(consent_text)defprocess_with_consent(self,frame):ifnotself.user_consent['granted']:returnframe# Unverarbeiteten Frame zurückgebenifself.consent_expired():self.user_consent=self.request_consent()returnself.detect_faces(frame)ifself.user_consent['granted']elseframe
Datenminimierung
Implementiere Datenminimierungs-Prinzipien:
Sammle nur Notwendiges: Wenn du nur Face Detection für Foto-Organisation brauchst, sammle keine Identitätsinformationen.
Minimiere Speicherung: Verarbeite und lösche Daten so schnell wie möglich.
Sichere Speicherung: Falls Daten gespeichert werden müssen, nutze Verschlüsselung und Zugriffskontrolle.
Durch Implementierung dieser Empfehlungen von Anfang an kannst du Face Detection Systeme erstellen, die Nutzer-Privatsphäre respektieren, Fairness fördern und öffentliches Vertrauen in KI-Technologien unterstützen.
Zukunftsempfehlungen
Die Landschaft für Face Detection und Tracking Lösungen entwickelt sich weiterhin schnell. Hier sind einige Schlüsseltrends, die du beachten solltest:
Edge-Optimierung bleibt Schlüsselfokus, mit Modellen, die immer effizienter werden bei erhaltener Genauigkeit
Datenschutz-Priorität gewinnt an Bedeutung, mit mehr Apps, die Verarbeitung auf Gerät statt Cloud-Lösungen verlagern
Bias-Reduzierung wird Standard-Anforderung, mit Frameworks, die Fairness-Testing einschließen
Compliance-Übereinstimmung entsteht, um Entwicklern bei sich entwickelnden Datenschutzgesetzen zu helfen
Modellwahl für dein Projekt
Die richtige Face Detection Modellwahl hängt von der Balance deiner spezifischen Anforderungen ab. Starte mit diesen Entscheidungskriterien:
Für Anfänger: Beginne mit MediaPipe oder YOLOv8-face wegen ihrer exzellenten Dokumentation und Benutzerfreundlichkeit
Für mobile Apps: MediaPipe BlazeFace bietet unübertroffene mobile Optimierung
Für genauigkeitskritische Anwendungen: RetinaFace liefert Forschungs-Level Performance
Für Edge-Deployment: YOLOv10-face oder EdgeFace bieten bestes Größe-Performance-Verhältnis
Für Video-Tracking: ByteTrack gewährleistet überlegene Identitätskonsistenz zwischen Frames
Für datenschutzbewusste Apps: Priorität auf lokale Modelle wie MediaPipe oder leichtgewichtige YOLO-Varianten
Überprüfe die Performance mit deinen spezifischen Daten und in deiner Deployment-Umgebung. Die Metriken in diesem Artikel bieten nur einen Ausgangspunkt, da echte Performance je nach Bildqualität, Lichtbedingungen und Hardware-Spezifikationen variieren kann.