En este artículo comparamos modelos modernos para detección y tracking de rostros según criterios clave: velocidad, precisión y facilidad de despliegue. Analizamos ejemplos reales de código Python, optimización de rendimiento y aspectos éticos importantes.
El reconocimiento facial es una tecnología clave que impulsa múltiples soluciones: desde desbloquear smartphones hasta sistemas complejos de seguridad. Hoy en día el mercado ofrece decenas de modelos, cada uno prometiendo alta precisión y velocidad. ¿Pero cómo navegar esta diversidad y elegir el adecuado para tu proyecto específico?
Ya sea una app móvil con reconocimiento facial en tiempo real o un sistema de videovigilancia con altos requisitos de precisión, elegir el modelo correcto es crítico. Estudiar pruebas comparativas y revisiones de algoritmos líderes en detección y tracking facial es el primer paso hacia una implementación tecnológica efectiva. Este enfoque no solo ayudará a ahorrar recursos, sino también a lograr un rendimiento estable y rápido en condiciones reales.
Introducción a las Tecnologías
Panorama de Rendimiento
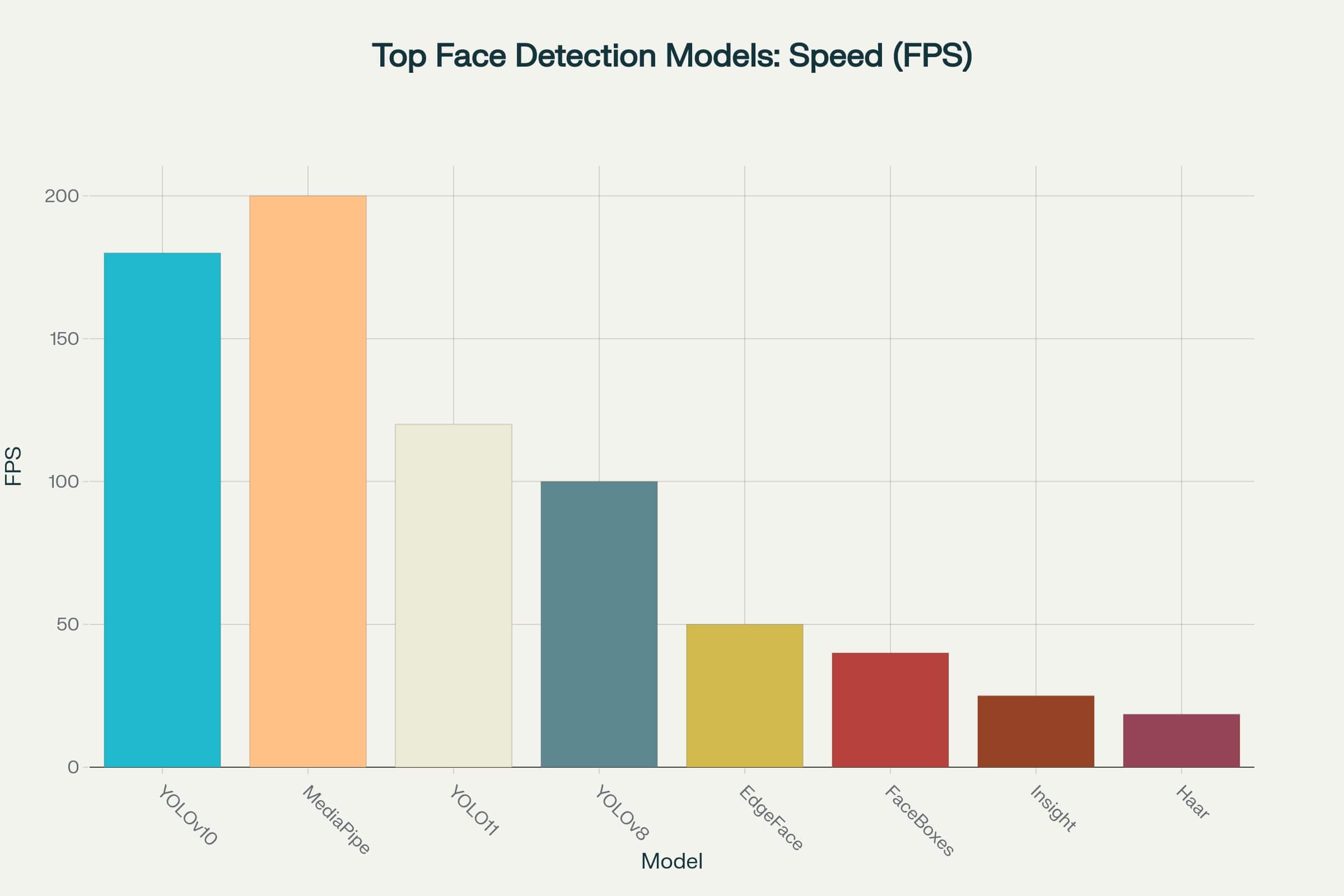
Los modelos modernos de detección facial se pueden categorizar por niveles de rendimiento basados en su relación velocidad-precisión. Las pruebas exhaustivas muestran que los algoritmos líderes han logrado resultados impresionantes: proporcionan alta velocidad de procesamiento sin pérdidas significativas de precisión.
Esto abre posibilidades para su uso incluso en aplicaciones con estrictas limitaciones de tiempo de respuesta - desde dispositivos móviles hasta dispositivos edge en sistemas de videovigilancia (haz clic en la imagen para abrir la versión ampliada).
Gráfico de velocidad de los mejores modelos de detección facial
Si te enfocas únicamente en velocidad, MediaPipe y YOLOv10 parecen favoritos claros, procesando de 180 a 200 cuadros por segundo. Esto los convierte en excelentes opciones para tareas en tiempo real donde es crucial la respuesta mínima.
Sin embargo, la alta velocidad de fotogramas no lo es todo. Sin suficiente precisión, incluso el modelo más rápido puede resultar ineficaz. Por ejemplo, en sistemas de videovigilancia o identificación biométrica, los modelos más lentos pero precisos aún tienen sus ventajas.
Compromisos de los Modelos
Al analizar el gráfico de velocidad (FPS - Frames Per Second) versus precisión (mAP - mean Average Precision), los modelos se agrupan en clusters distintos, reflejando compromisos clave en detección facial: el aumento de precisión a menudo viene acompañado de reducción de velocidad, y viceversa.
Gráfico de rendimiento de los mejores modelos de detección facial
Este diagrama revela cuatro categorías distintas de modelos:
Solo CPU (puntos grises) - modelos como Haar Cascade y DLib HOG proporcionan rendimiento básico sin necesidad de GPU. No destacan en velocidad, pero son perfectos para dispositivos con recursos limitados y sistemas embebidos.
Ligeros (puntos azules) - incluyen MediaPipe BlazeFace y varias versiones de YOLO. Estos modelos ofrecen excelente velocidad de procesamiento con un nivel razonable de precisión, siendo la opción óptima para la mayoría de aplicaciones en tiempo real.
Medios (puntos naranjas) - modelos como InsightFace SCRFD y EdgeFace proporcionan mayor precisión a velocidades moderadas. Se eligen cuando la precisión importa pero se requiere mantener un rendimiento decente.
Pesados (puntos rojos) - como RetinaFace y DSFD. Estos modelos demuestran precisión a nivel de investigación pero requieren recursos computacionales significativos. Están diseñados para tareas críticas donde es aceptable alta carga de hardware.
Implementación Práctica
Aquí tienes varios ejemplos de código Python para trabajar con diferentes modelos. Como puedes ver, no es tan complicado - las cosas básicas son bastante simples:
Inicio Rápido con YOLOv8-Face
YOLOv8 representa un excelente equilibrio entre rendimiento y facilidad de uso. Este modelo es perfecto para desarrolladores principiantes.
fromultralyticsimportYOLOimportcv2# Cargar el modelomodel=YOLO('yolov8n-face.pt')# Procesar una imagen únicaresults=model('path/to/your/image.jpg')# Procesar stream de videocap=cv2.VideoCapture(0)whileTrue:ret,frame=cap.read()ifnotret:breakresults=model(frame)annotated_frame=results[0].plot()cv2.imshow('Face Detection',annotated_frame)ifcv2.waitKey(1)&0xFF==ord('q'):breakcap.release()cv2.destroyAllWindows()
Plataforma Móvil con MediaPipe
MediaPipe está optimizado para plataformas móviles y proporciona rendimiento estable incluso en dispositivos de gama media.
importmediapipeasmpimportcv2# Inicializar MediaPipe Face Detection una vezmp_face_detection=mp.solutions.face_detectionmp_drawing=mp.solutions.drawing_utilscap=cv2.VideoCapture(0)# Usar operador 'with' fuera del bucle para gestión adecuada de recursoswithmp_face_detection.FaceDetection(model_selection=0,min_detection_confidence=0.5)asface_detection:whilecap.isOpened():success,image=cap.read()ifnotsuccess:print("Ignorando cuadro vacío de cámara.")continue# Para mejorar rendimiento, opcionalmente marcar imagen como no escribible# para pasar por referencia.image.flags.writeable=Falseimage=cv2.cvtColor(image,cv2.COLOR_BGR2RGB)results=face_detection.process(image)# Dibujar anotaciones de detección facial en la imagen.image.flags.writeable=Trueimage=cv2.cvtColor(image,cv2.COLOR_RGB2BGR)ifresults.detections:fordetectioninresults.detections:mp_drawing.draw_detection(image,detection)cv2.imshow('MediaPipe Face Detection',image)ifcv2.waitKey(5)&0xFF==27:# Tecla ESCbreakcap.release()cv2.destroyAllWindows()
Avanzada con RetinaFace
Para tareas que requieren máxima precisión, RetinaFace sigue siendo el estándar dorado en detección facial.
El tracking facial es un proceso de seguimiento continuo de rostros en secuencias de video que va mucho más allá de la simple detección única. A diferencia de la detección, el tracking requiere identificación estable de rostros a través de múltiples cuadros, lo que impone altas demandas en el rendimiento de los algoritmos.
El gráfico muestra una comparación de modelos de tracking populares por dos métricas clave:
Velocidad de Procesamiento (FPS) - cuadros por segundo, determinando el rendimiento del modelo
Precisión (puntuación MOTA) - indicador integral de calidad de tracking, considerando errores de identificación
¿Qué es MOTA?
MOTA (Multiple Object Tracking Accuracy) es una métrica clave para evaluar la calidad del tracking de objetos (incluyendo rostros) que considera tres tipos principales de errores:
False Negatives (FN) - objetos perdidos (el tracker no encontró un objeto real).
ID Switches (IDs) - cambios de identificador (el tracker “confundió” las etiquetas de objetos durante cruce o desaparición temporal).
Fórmula de Cálculo
$$
MOTA = 1 - \frac{\sum (FP + FN + IDs)}{\sum \text{Número total de objetos en cada cuadro}}
$$
Características
Rango de valores: de $-\infty$ a 1 (más cerca de 1 es mejor).
Ejemplo: MOTA = 0.85 significa que el tracker cometió errores en 15% de los casos.
Indicador integral: combina todos los errores principales de tracking en una puntuación.
Crítico para tareas de videovigilancia, análisis de comportamiento y sistemas autónomos donde la estabilidad de identificación es importante.
Diferencia de Otras Métricas
MOTP (Multiple Object Tracking Precision) - evalúa precisión de localización de objetos pero no considera errores de identificación.
IDF1 - se enfoca en corrección de coincidencia de ID entre cuadros.
Para tu gráfico, MOTA alto en un modelo (ej., FairMOT o ByteTrack) indica su confiabilidad en escenas complejas (ej., con oclusión facial o cambios de iluminación).
Entre las soluciones presentadas (Deeperport, FairMOT, ByteTrack y otros) se observa variación significativa de rendimiento - algunos modelos muestran alta velocidad a expensas de precisión, mientras otros proporcionan tracking preciso pero trabajan más lento.
La elección del modelo óptimo siempre depende de la tarea específica: las aplicaciones en tiempo real priorizan velocidad (FPS), los sistemas analíticos priorizan precisión (MOTA). Los enfoques híbridos (ej., FaceTracker difu) son particularmente interesantes, intentando equilibrar estos requisitos conflictivos.
Comparación de los mejores modelos de detección facial
ByteTrack demuestra el mejor equilibrio velocidad-precisión: a 171 FPS récord mantiene una puntuación MOTA alta. Esto lo convierte en la opción óptima para sistemas en tiempo real donde tanto el rendimiento como la estabilidad de identificación de objetos son críticos.
ByteTrack para Video
importcv2fromyolox.tracker.byte_trackerimportBYTETrackerfromultralyticsimportYOLOclassVideoTracker:def__init__(self):self.model=YOLO('yolov8n-face.pt')self.tracker=BYTETracker(frame_rate=30)deftrack_video(self,video_path):cap=cv2.VideoCapture(video_path)frame_id=0whileTrue:ret,frame=cap.read()ifnotret:break# Detecciónresults=self.model(frame)# Convertir a formato de trackingdetections=[]iflen(results[0].boxes)>0:boxes=results[0].boxes.xyxy.cpu().numpy()scores=results[0].boxes.conf.cpu().numpy()forbox,scoreinzip(boxes,scores):detections.append([*box,score])# Actualizar trackertracks=self.tracker.update(np.array(detections),frame.shape[:2],frame.shape[:2])# Dibujar tracksfortrackintracks:x1,y1,x2,y2,track_id=track[:5]cv2.rectangle(frame,(int(x1),int(y1)),(int(x2),int(y2)),(0,255,0),2)cv2.putText(frame,f'ID: {int(track_id)}',(int(x1),int(y1)-10),cv2.FONT_HERSHEY_SIMPLEX,0.6,(0,255,0),2)cv2.imshow('Face Tracking',frame)ifcv2.waitKey(1)&0xFF==ord('q'):breakframe_id+=1cap.release()cv2.destroyAllWindows()# Usotracker=VideoTracker()tracker.track_video('path/to/video.mp4')
Para aplicaciones móviles enfocadas en UX fluido, la velocidad de reconocimiento facial es críticamente importante - aquí son óptimos los modelos con 30-60+ FPS que funcionan incluso en dispositivos débiles.
¿Por qué es importante?
Sin lag: 60 FPS = procesamiento de cada cuadro en 16 ms (frecuencia de actualización de pantalla de smartphones).
Optimización hardware: Uso de NPU/GPU del teléfono (ej., CoreML en iOS, NNAPI en Android).
Caching: Escenarios predecibles (ej., re-reconocimiento del mismo rostro) aceleran el trabajo.
Ejemplo: Los filtros de Snapchat funcionan en tiempo real precisamente gracias a tales optimizaciones. Así que elegir un modelo con buen equilibrio velocidad/precisión es uno de los factores clave de éxito de una aplicación móvil.
# Implementación de detector facial para dispositivos móviles.importmediapipeasmpimportcv2importnumpyasnpimporttimeclassMobileFaceDetector:"""
Clase para detección facial en stream de video, optimizada para
rendimiento en dispositivos móviles.
Incluye salto de cuadros para lograr FPS objetivo y renderizado
suave de marcos para evitar "parpadeo".
"""def__init__(self,model_selection=0,min_detection_confidence=0.7):"""
Inicializa detector facial.
Args:
model_selection (int): Selección de modelo. 0 para radio corto (hasta 2 metros),
1 para largo (hasta 5 metros).
min_detection_confidence (float): Umbral mínimo de confianza para detección.
"""# --- Inicialización MediaPipe Face Detection ---# Crear instancia con parámetros dados.self.face_detection=mp.solutions.face_detection.FaceDetection(model_selection=model_selection,min_detection_confidence=min_detection_confidence,)# --- Variables para renderizado y FPS ---# Almacenar últimas detecciones exitosas para dibujarlas en cuadros saltados.self.last_results=None# Guardar dimensiones originales del cuadro para escalado correcto.self.original_width=0self.original_height=0def_draw_detections(self,frame,detections):"""
Función auxiliar para dibujar marcos en cuadro.
Args:
frame (np.ndarray): Cuadro en el que dibujar.
detections: Resultados de detección de MediaPipe.
"""ifdetections:fordetectionindetections:# Obtener coordenadas relativas de marco (de 0.0 a 1.0).bboxC=detection.location_data.relative_bounding_box# Escalar coordenadas de vuelta al tamaño original del cuadro.x=int(bboxC.xmin*self.original_width)y=int(bboxC.ymin*self.original_height)width=int(bboxC.width*self.original_width)height=int(bboxC.height*self.original_height)# Dibujar rectángulo en cuadro original.cv2.rectangle(frame,(x,y),(x+width,y+height),(0,255,0),2)returnframedefprocess_frame(self,frame,target_width=320):"""
Procesa un cuadro del stream de video.
Args:
frame (np.ndarray): Cuadro de entrada en formato BGR.
target_width (int): Ancho objetivo para procesamiento. El cuadro será
proporcionalmente reducido a este ancho.
Returns:
np.ndarray: Cuadro con marcos dibujados.
"""self.original_height,self.original_width=frame.shape[:2]# --- Optimización 1: Reducción de resolución ---# Preservar relación de aspecto.scale=target_width/self.original_widthsmall_frame=cv2.resize(frame,(0,0),fx=scale,fy=scale,interpolation=cv2.INTER_AREA)# --- Optimización 2: Conversión de color y mejora de rendimiento ---# MediaPipe requiere RGB. Convertir una vez.rgb_small_frame=cv2.cvtColor(small_frame,cv2.COLOR_BGR2RGB)# Marcar cuadro como "solo lectura" para aceleración.rgb_small_frame.flags.writeable=False# --- Detección facial ---results=self.face_detection.process(rgb_small_frame)# Restaurar flag si necesitas trabajar más con el cuadro.rgb_small_frame.flags.writeable=True# --- Renderizado ---# Si detección fue exitosa, guardar resultados.ifresults.detections:self.last_results=results.detections# Dibujar marcos en cuadro original. Si no se encontraron rostros en cuadro actual# pero estaban en previos, usar datos antiguos para suavidad.processed_frame=self._draw_detections(frame,self.last_results)returnprocessed_framedefclose(self):"""Liberar recursos MediaPipe."""self.face_detection.close()# --- Ejemplo de uso con webcam ---if__name__=='__main__':# Inicializar detectordetector=MobileFaceDetector(min_detection_confidence=0.5)# Capturar video de webcam (0 - usualmente cámara integrada)cap=cv2.VideoCapture(0)ifnotcap.isOpened():print("Error: no se pudo abrir webcam.")exit()# Variables para cálculo de FPSprev_frame_time=0new_frame_time=0try:whileTrue:# Leer cuadro de cámarasuccess,frame=cap.read()ifnotsuccess:print("No se pudo obtener cuadro. Terminando.")break# Voltear cuadro para efecto "espejo"frame=cv2.flip(frame,1)# --- Saltar procesamiento para lograr FPS objetivo ---# Esto es menos importante con nueva lógica de renderizado, pero aún ahorra recursos# Aquí puedes implementar tu lógica de salto de cuadros si es necesario# Procesar cuadroprocessed_frame=detector.process_frame(frame)# --- Cálculo y visualización de FPS ---new_frame_time=time.time()fps=1/(new_frame_time-prev_frame_time)prev_frame_time=new_frame_timecv2.putText(processed_frame,f'FPS: {int(fps)}',(10,30),cv2.FONT_HERSHEY_SIMPLEX,1,(0,255,0),2)# Mostrar resultadocv2.imshow('Mobile Face Detection',processed_frame)# Salir al presionar tecla 'q'ifcv2.waitKey(1)&0xFF==ord('q'):breakfinally:# Liberar recursosprint("Liberando recursos...")cap.release()detector.close()cv2.destroyAllWindows()
Stack Recomendado:
Para detección:
MediaPipe Face Detection (BlazeFace) - óptimo para móviles
Para tracking:
MediaPipe Face Mesh (468 puntos) - si necesitas landmarks
Lightweight OpenPose - para tracking simplificado
Rendimiento:
60-100 FPS en smartphone promedio (Snapdragon 7xx)
Hasta 200 FPS en flagship (Snapdragon 8 Gen 2/Apple A15+)
Memoria:
Mínimo 2GB RAM para funcionalidad básica
3-4GB+ para escenarios complejos (detección+tracking simultáneo)
Optimización:
Uso de TFLite con aceleración hardware (GPU/NPU)
Caching de resultados para escenas estáticas
Reducción dinámica de calidad durante sobrecalentamiento del dispositivo
Sistemas de Seguridad
Las aplicaciones de seguridad requieren máxima precisión con latencia aceptable:
# Sistema de seguridad con tracking, verificación,# reconocimiento optimizado y visualización.importcv2importnumpyasnpimporttimeimportosimportpicklefromtypingimportDict,List,Any,Optional,Tuple# --- Se asume que estas librerías están instaladas ---# pip install opencv-python numpy# pip install insightface# pip install retinaface-pytorch deep-sort-realtime## Importante: InsightFace requiere onnxruntime-gpu. DeepSort también tiene dependencias.# La instalación puede requerir pasos adicionales, incluyendo descarga de modelos.fromretinafaceimportRetinaFacefromdeep_sort_realtime.deepsort_trackerimportDeepSortfrominsightface.appimportFaceAnalysisclassAdvancedSecuritySystem:"""
Sistema de seguridad integral que combina detección, tracking y
reconocimiento facial con optimizaciones para tiempo real.
"""def__init__(self,db_path:str,detection_thresh:float=0.9,recognition_thresh:float=0.5):"""
Inicialización de todos los componentes del sistema.
Args:
db_path (str): Ruta al archivo de base de datos de rostros (.pkl).
detection_thresh (float): Umbral de confianza para detector facial.
recognition_thresh (float): Umbral de similitud para reconocimiento facial.
"""print("Inicializando sistema de seguridad...")# --- Detector facial (RetinaFace) ---# RetinaFace funciona bien para detectar rostros "difíciles".# Para CPU puedes usar 'mobilenet', para GPU - 'resnet50'.self.detector=RetinaFace(gpu_id=0)# Especifica -1 para uso de CPUprint("Detector facial (RetinaFace) inicializado.")# --- Tracker (DeepSort) ---# max_age: cuántos cuadros puede existir un track sin detección.# n_init: cuántas veces debe detectarse objeto para iniciar tracking.self.tracker=DeepSort(max_age=30,n_init=3)print("Tracker (DeepSort) inicializado.")# --- Reconocedor facial (InsightFace) ---# Usar CUDA para máximo rendimiento.self.recognizer=FaceAnalysis(name='buffalo_l',providers=['CUDAExecutionProvider'])self.recognizer.prepare(ctx_id=0)# ctx_id=0 para GPU, -1 para CPUprint("Reconocedor facial (InsightFace) inicializado.")# --- Parámetros y base de datos ---self.detection_thresh=detection_threshself.recognition_thresh=recognition_threshself.face_db=self._load_face_database(db_path)# Diccionario para almacenar identidades ya reconocidas por track_id# {track_id: {"identity": "Name", "verified": True/False}}self.tracked_identities:Dict[str,Dict[str,Any]]={}def_load_face_database(self,db_path:str)->Optional[Dict[str,np.ndarray]]:"""Carga base de datos de embeddings pre-creada."""ifnotos.path.exists(db_path):print(f"Error: Archivo de base de datos no encontrado en ruta: {db_path}")print("Por favor, primero crea la base de datos usando create_database_from_folder().")returnNonewithopen(db_path,'rb')asf:db=pickle.load(f)print(f"Base de datos facial cargada exitosamente. Encontradas {len(db)} identidades.")returndbdef_extract_embedding(self,frame:np.ndarray,bbox:np.ndarray)->Optional[np.ndarray]:"""Extrae embedding (vector de características) del área facial."""# Recortar rostro de forma segura, recortando coordenadas a límites del cuadroh,w=frame.shape[:2]x1,y1,x2,y2=np.maximum(0,bbox).astype(int)x2,y2=min(x2,w),min(y2,h)face_img=frame[y1:y2,x1:x2]ifface_img.size==0:returnNone# Usar InsightFace para obtener embeddingfaces=self.recognizer.get(face_img)returnfaces[0].embeddingiffaceselseNonedef_find_match(self,embedding:np.ndarray)->Tuple[str,float]:"""Encuentra rostro más similar en base de datos."""ifembeddingisNoneorself.face_dbisNone:return"Unknown",0.0best_match="Unknown"best_score=0.0# Usar similitud coseno (producto punto de vectores normalizados)forname,db_embedinself.face_db.items():score=np.dot(embedding,db_embed)/(np.linalg.norm(embedding)*np.linalg.norm(db_embed))ifscore>self.recognition_threshandscore>best_score:best_score=scorebest_match=namereturnbest_match,best_scoredefprocess_frame(self,frame:np.ndarray)->np.ndarray:"""
Ciclo completo de procesamiento de un cuadro: detección, tracking, reconocimiento.
Returns:
np.ndarray: Cuadro con información dibujada (marcos, IDs, nombres).
"""ifself.face_dbisNone:cv2.putText(frame,"Face DB not loaded!",(20,40),cv2.FONT_HERSHEY_SIMPLEX,1,(0,0,255),2)returnframe# --- 1. Detección ---# RetinaFace devuelve diccionario que necesita conversióndetections_raw=self.detector.detect(frame,threshold=self.detection_thresh)# Conversión a formato entendible por DeepSort: [[x1, y1, x2, y2], confidence]deepsort_detections=[]forface_dataindetections_raw:x1,y1,x2,y2,conf=face_datadeepsort_detections.append(([x1,y1,x2,y2],conf,"face"))# --- 2. Tracking ---tracks=self.tracker.update_tracks(deepsort_detections,frame=frame)# --- 3. Reconocimiento y Visualización ---fortrackintracks:ifnottrack.is_confirmed():continuetrack_id=track.track_idbbox=track.to_tlbr()# (x1, y1, x2, y2)identity_info=self.tracked_identities.get(track_id)# OPTIMIZACIÓN: Reconocer solo tracks nuevosifidentity_infoisNone:embedding=self._extract_embedding(frame,bbox)name,score=self._find_match(embedding)self.tracked_identities[track_id]={"identity":name,"score":score}identity_info=self.tracked_identities[track_id]# --- Visualización ---name=identity_info.get("identity","Unknown")score=identity_info.get("score",0.0)color=(0,255,0)ifname!="Unknown"else(0,0,255)# Dibujar marcocv2.rectangle(frame,(int(bbox[0]),int(bbox[1])),(int(bbox[2]),int(bbox[3])),color,2)# Formar texto para etiquetalabel=f"ID: {track_id} | {name} ({score:.2f})"# Dibujar etiquetacv2.putText(frame,label,(int(bbox[0]),int(bbox[1])-10),cv2.FONT_HERSHEY_SIMPLEX,0.7,color,2)returnframedefcreate_database_from_folder(self,folder_path:str,output_db_path:str):"""
Crea base de datos de embeddings desde carpeta con imágenes.
Estructura de carpeta:
- folder_path/
- persona_1/
- imagen1.jpg
- imagen2.png
- persona_2/
- foto.jpg
"""face_db={}print(f"Creando base de datos desde carpeta: {folder_path}")forperson_nameinos.listdir(folder_path):person_folder=os.path.join(folder_path,person_name)ifnotos.path.isdir(person_folder):continueembeddings=[]forimage_nameinos.listdir(person_folder):image_path=os.path.join(person_folder,image_name)img=cv2.imread(image_path)ifimgisNone:continue# Obtener embedding para primer rostro encontrado en fotofaces=self.recognizer.get(img)iffaces:embeddings.append(faces[0].embedding)ifembeddings:# Promediar embeddings para mayor estabilidadface_db[person_name]=np.mean(embeddings,axis=0)print(f"-> Rostro encontrado y procesado: {person_name}")# Guardar base en archivowithopen(output_db_path,'wb')asf:pickle.dump(face_db,f)print(f"Base de datos creada exitosamente y guardada en: {output_db_path}")# --- Ejemplo de uso ---if__name__=='__main__':DB_FILE="face_db.pkl"DB_SOURCE_FOLDER="face_images"# Carpeta con fotos para crear BD# --- Paso 1: Crear base de datos (ejecutar una vez) ---# Para este paso necesitas crear carpeta face_images con subcarpetas# de nombres de personas conteniendo sus fotografías.ifnotos.path.exists(DB_FILE):print("Base de datos no encontrada. Iniciando proceso de creación...")# Crear carpeta temporal para ejemplo si no existeifnotos.path.exists(DB_SOURCE_FOLDER):os.makedirs(os.path.join(DB_SOURCE_FOLDER,"persona_ejemplo"))print(f"Carpeta de ejemplo creada: {DB_SOURCE_FOLDER}/persona_ejemplo")print("Por favor coloca archivos .jpg con rostros ahí y reinicia el script.")exit()# Inicializar sistema solo para creación de BDtemp_system=AdvancedSecuritySystem(db_path=DB_FILE)temp_system.create_database_from_folder(DB_SOURCE_FOLDER,DB_FILE)print("-"*30)# --- Paso 2: Ejecutar sistema en stream de video ---system=AdvancedSecuritySystem(db_path=DB_FILE)cap=cv2.VideoCapture(0)# 0 para webcam o ruta a archivo de videoifnotcap.isOpened():print("Error: no se pudo abrir stream de video.")exit()prev_time=0try:whileTrue:success,frame=cap.read()ifnotsuccess:break# Procesar cuadroprocessed_frame=system.process_frame(frame)# Calcular y mostrar FPScurr_time=time.time()fps=1/(curr_time-prev_time)prev_time=curr_timecv2.putText(processed_frame,f"FPS: {int(fps)}",(20,80),cv2.FONT_HERSHEY_SIMPLEX,1,(0,255,0),2)cv2.imshow("Advanced Security System",processed_frame)ifcv2.waitKey(1)&0xFF==ord('q'):breakfinally:print("Terminando y liberando recursos.")cap.release()cv2.destroyAllWindows()
Stack Recomendado:
Para detección:
RetinaFace (ResNet50) - máxima precisión para tareas críticas
SCRFD - versión optimizada para dispositivos edge
Para tracking:
DeepSORT - mejor estabilidad durante oclusiones
ByteTrack - máximo rendimiento (hasta 50 FPS)
Para reconocimiento:
InsightFace (buffalo_l) - precisión estado del arte
ArcFace - alternativa con soporte multiidioma
Rendimiento:
15-25 FPS (Full HD, pipeline completo en RTX 3070)
Hasta 50 FPS con optimización TensorRT
Memoria:
Mínimo 8GB VRAM para configuración básica
12GB+ VRAM para trabajar con streams 4K
Optimización:
Uso de TensorRT/ONNX Runtime para aceleración
Procesamiento en cascada (detección preliminar rápida → verificación precisa)
Procesamiento pipeline asíncrono para sistemas distribuidos
Seguridad:
Verificación liveness obligatoria (anti-spoofing)
Encriptación de embeddings en base de datos
Timestamps para auditoría de acceso
Edge e IoT
Ambientes con recursos limitados requieren optimización cuidadosa:
# Implementación de detección y tracking facial para dispositivos Edge# usando TensorFlow Lite.importcv2importnumpyasnpimporttimeimportargparsefromtypingimportList,Dict,Any,Tuple,Optional# Este script requiere tflite_runtime.# Instalación: pip install tflite-runtimetry:fromtflite_runtime.interpreterimportInterpreterexceptImportError:print("Error: tflite_runtime no encontrado. Por favor instálalo:")print("pip install tflite-runtime")exit()classEdgeFacePipeline:"""
Clase para detección y tracking facial en dispositivos Edge usando TFLite.
Incluye optimizaciones hardware y tracker IOU ligero.
"""def__init__(self,model_path:str,device:str='cpu',conf_thresh:float=0.7):"""
Inicialización del pipeline.
Args:
model_path (str): Ruta al archivo de modelo .tflite.
device (str): Dispositivo para ejecución ('cpu' o 'npu').
conf_thresh (float): Umbral de confianza para detección facial.
"""print(f"Cargando modelo TFLite desde: {model_path}")self.interpreter=Interpreter(model_path=model_path)self.interpreter.allocate_tensors()self.input_details=self.interpreter.get_input_details()self.output_details=self.interpreter.get_output_details()# Importante: obtener dimensiones exactas que requiere el modeloself.input_height=self.input_details[0]['shape'][1]self.input_width=self.input_details[0]['shape'][2]self.conf_thresh=conf_threshself.tracked_faces:List[Dict[str,Any]]=[]self.next_track_id=0self.iou_thresh=0.4# Umbral IOU para trackingself._configure_device(device)print(f"Pipeline inicializado para dispositivo: {device}")def_configure_device(self,device:str):"""Aplica optimizaciones específicas de hardware."""cv2.setUseOptimized(True)# Configuraciones NPU (Neural Processing Unit)ifdevice=='npu':# Aquí pueden ir delegados específicos para NPU, ej., 'libedgetpu.so.1'# self.interpreter = Interpreter(model_path=self.model_path,# experimental_delegates=[load_delegate('libedgetpu.so.1')])self.interpreter.set_num_threads(1)print("Optimizaciones NPU aplicadas (configuración simplificada).")# Optimizaciones CPUelse:self.interpreter.set_num_threads(4)print("Optimizaciones CPU aplicadas (4 hilos).")def_preprocess(self,frame:np.ndarray)->np.ndarray:"""
Preparar cuadro para red neuronal: redimensionar y normalizar.
"""# Redimensionar a dimensiones exactas de entrada del modelo ---resized_frame=cv2.resize(frame,(self.input_width,self.input_height))# Convertir a RGB si el modelo lo requierergb_frame=cv2.cvtColor(resized_frame,cv2.COLOR_BGR2RGB)# Normalización y agregar dimensión batch# Muchos modelos TFLite esperan float32 en rango [-1, 1] o [0, 1]# o uint8 [0, 255]. Revisa documentación de tu modelo.# Aquí asumimos float32 [0, 1].input_data=np.expand_dims(rgb_frame,axis=0).astype(np.float32)/255.0returninput_datadefprocess_frame(self,frame:np.ndarray)->List[Dict[str,Any]]:"""
Ciclo completo de procesamiento: detección y tracking.
Args:
frame (np.ndarray): Cuadro de entrada en formato BGR.
Returns:
List[Dict[str, Any]]: Lista de rostros rastreados con sus IDs y coordenadas.
"""original_h,original_w=frame.shape[:2]# 1. Preprocesamiento de cuadroinput_data=self._preprocess(frame)# 2. Inferencia del modeloself.interpreter.set_tensor(self.input_details[0]['index'],input_data)self.interpreter.invoke()# 3. Obtener y postprocesar resultados# El formato de salida puede diferir para diferentes modelos.# Asumimos que el modelo devuelve [boxes, scores].boxes=self.interpreter.get_tensor(self.output_details[0]['index'])[0]scores=self.interpreter.get_tensor(self.output_details[1]['index'])[0]current_detections=[]fori,scoreinenumerate(scores):ifscore>self.conf_thresh:# Coordenadas devueltas en forma normalizada [ymin, xmin, ymax, xmax]ymin,xmin,ymax,xmax=boxes[i]# Escalar coordenadas al tamaño original del cuadroabs_xmin=int(xmin*original_w)abs_ymin=int(ymin*original_h)abs_xmax=int(xmax*original_w)abs_ymax=int(ymax*original_h)current_detections.append({'bbox':(abs_xmin,abs_ymin,abs_xmax,abs_ymax),'score':float(score)})# 4. Actualizar trackerself._update_tracker(current_detections)returnself.tracked_facesdef_update_tracker(self,new_detections:List[Dict[str,Any]]):"""Actualiza tracks basado en nuevas detecciones usando IOU."""ifnotself.tracked_faces:# Si no hay tracks, inicializarlos desde nuevas deteccionesfordetinnew_detections:det['track_id']=self.next_track_iddet['age']=0# Contador de "edad" del trackself.tracked_faces.append(det)self.next_track_id+=1returnmatched_indices=set()# Intentar emparejar nuevas detecciones con tracks existentesfori,trackinenumerate(self.tracked_faces):best_match_iou=0best_match_idx=-1forj,detinenumerate(new_detections):ifjinmatched_indices:continueiou=self._calculate_iou(track['bbox'],det['bbox'])ifiou>self.iou_threshandiou>best_match_iou:best_match_iou=ioubest_match_idx=jifbest_match_idx!=-1:# Actualizar tracktrack['bbox']=new_detections[best_match_idx]['bbox']track['age']=0# Reiniciar edad ya que track fue encontradomatched_indices.add(best_match_idx)else:# Aumentar edad si track no fue encontradotrack['age']+=1# Agregar nuevos tracks para detecciones no emparejadasforj,detinenumerate(new_detections):ifjnotinmatched_indices:det['track_id']=self.next_track_iddet['age']=0self.tracked_faces.append(det)self.next_track_id+=1# Remover tracks antiguos que no han sido vistos por un tiempoself.tracked_faces=[tfortinself.tracked_facesift['age']<15]@staticmethoddef_calculate_iou(box1:Tuple,box2:Tuple)->float:"""Calcula Intersection over Union (IOU) para dos marcos."""x1,y1,x2,y2=box1x3,y3,x4,y4=box2xi1,yi1=max(x1,x3),max(y1,y3)xi2,yi2=min(x2,x4),min(y2,y4)inter_area=max(0,xi2-xi1)*max(0,yi2-yi1)box1_area=(x2-x1)*(y2-y1)box2_area=(x4-x3)*(y4-y3)union_area=box1_area+box2_area-inter_areareturninter_area/union_areaifunion_area>0else0.0defdraw_results(frame:np.ndarray,faces:List[Dict[str,Any]]):"""Dibujar resultados en cuadro."""forfaceinfaces:# Usar coordenadas para dibujarxmin,ymin,xmax,ymax=face['bbox']track_id=face['track_id']cv2.rectangle(frame,(xmin,ymin),(xmax,ymax),(0,255,0),2)label=f"ID: {track_id}"cv2.putText(frame,label,(xmin,ymin-10),cv2.FONT_HERSHEY_SIMPLEX,0.7,(0,255,0),2)# Ejemplo de usoif__name__=="__main__":parser=argparse.ArgumentParser(description="Detección Facial en Dispositivos Edge")parser.add_argument("--model",type=str,required=True,help="Ruta al archivo de modelo .tflite.")parser.add_argument("--device",type=str,default='cpu',choices=['cpu','npu'],help="Dispositivo para ejecutar inferencia.")parser.add_argument("--video",type=str,help="Ruta a archivo de video. Si no se proporciona, usa webcam.")args=parser.parse_args()pipeline=EdgeFacePipeline(model_path=args.model,device=args.device)cap=cv2.VideoCapture(args.videoifargs.videoelse0)ifnotcap.isOpened():print(f"Error: no se pudo abrir fuente de video.")exit()prev_time=0try:whileTrue:ret,frame=cap.read()ifnotret:break# Procesar cuadrotracked_faces=pipeline.process_frame(frame)# Visualizar resultadosdraw_results(frame,tracked_faces)# Mostrar FPScurr_time=time.time()fps=1/(curr_time-prev_time)prev_time=curr_timecv2.putText(frame,f"FPS: {int(fps)}",(10,30),cv2.FONT_HERSHEY_SIMPLEX,1,(0,0,255),2)cv2.imshow('Edge Face Detection',frame)ifcv2.waitKey(1)&0xFF==ord('q'):breakfinally:print("Terminando y liberando recursos.")cap.release()cv2.destroyAllWindows()
Stack Recomendado:
Para detección:
YOLOv10n-face (versión Nano) – hasta 180 FPS en Raspberry Pi
Haar Cascades – requisitos mínimos (funciona incluso en ESP32)
La gestión eficiente de memoria y recursos computacionales afecta significativamente el rendimiento del sistema.
importgcimporttorchdefoptimize_gpu_memory():"""Limpieza de memoria GPU después del procesamiento"""iftorch.cuda.is_available():torch.cuda.empty_cache()gc.collect()defbatch_processing(image_list,model,batch_size=4):"""Procesamiento por lotes para optimización de throughput"""results=[]foriinrange(0,len(image_list),batch_size):batch=image_list[i:i+batch_size]batch_results=model(batch)results.extend(batch_results)# Limpieza de memoria después de cada loteoptimize_gpu_memory()returnresults
Procesamiento Multi-hilo
Separar los procesos de lectura, procesamiento y visualización de cuadros permite utilizar al máximo los recursos disponibles del sistema.
Los modelos de detección facial pueden mostrar diferencias de rendimiento entre varios grupos demográficos. Muchos modelos funcionan menos precisamente (el error puede ser 30% mayor) al detectar y rastrear rostros de personas con tonos de piel más oscuros, mujeres y personas mayores.
Algunos consejos para evitar tales situaciones:
Prueba en diferentes grupos demográficos: Siempre evalúa el rendimiento de tu modelo elegido para diferentes grupos de edad, géneros y etnias usando conjuntos de datos de prueba diversos.
Monitorea rendimiento en el mundo real: Evalúa continuamente cómo funciona tu sistema para diferentes grupos de usuarios en entornos de producción.
Considera modelos especializados: Algunos frameworks, como MediaPipe y nuevas variantes YOLO, fueron entrenados específicamente en conjuntos de datos más diversos para reducir el sesgo.
# Ejemplo: framework de prueba de sesgodefevaluate_model_bias(model,test_datasets):"""
Evaluar rendimiento del modelo por grupos demográficos
"""results={}forgroup_name,datasetintest_datasets.items():detections=[]forimage_pathindataset['images']:result=model(image_path)detections.append(result)# Calcular métricas para este grupo demográficoaccuracy=calculate_accuracy(detections,dataset['ground_truth'])results[group_name]={'accuracy':accuracy,'sample_size':len(dataset['images'])}returnresults# Ejemplo de usodemographic_results=evaluate_model_bias(model,{'young':young_adult_dataset,'elderly':elderly_dataset,'diverse':diverse_dataset})
Nota: Los fragmentos de código en esta sección representan frameworks conceptuales. Las funciones auxiliares como calculate_accuracy, present_consent_dialog, o implementaciones específicas de UI deben desarrollarse basándose en los requisitos de tu aplicación y frameworks elegidos.
Prioridad de Privacidad
Elegir entre procesamiento de datos local o en la nube puede tener implicaciones significativas para la privacidad:
Ventajas del procesamiento local:
Los datos personales nunca salen del dispositivo del usuario
Se reduce el riesgo de filtraciones de datos
Cumplimiento con regulaciones como GDPR
El usuario mantiene control sobre sus datos biométricos
Obtener Consentimiento
Las tecnologías de tracking facial también plantean preguntas importantes sobre consentimiento y transparencia:
Mejores prácticas para consentimiento:
Los usuarios deben entender qué datos se recopilan y cómo se usan
Proporciona opciones de opt-out del tracking manteniendo funcionalidad central
Pide periódicamente a los usuarios confirmar su consentimiento
Ejemplo de implementación:
classConsentAwareFaceTracker:def__init__(self):self.user_consent=self.check_user_consent()self.tracking_enabled=Falsedefcheck_user_consent(self):# Verificar preferencias guardadas del usuario# Devolver estado de consentimiento y timestamppassdefrequest_consent(self):"""
Presentar diálogo claro de consentimiento al usuario
"""consent_text="""
Esta aplicación usa detección facial para:
- Mejorar tu experiencia con filtros AR
- Enfoque automático de cámara en rostros
Tus datos faciales:
- Se procesan completamente en tu dispositivo
- Nunca se guardan ni transmiten
- Pueden deshabilitarse en cualquier momento en configuración
¿Aceptas la detección facial? [Sí/No]
"""returnself.present_consent_dialog(consent_text)defprocess_with_consent(self,frame):ifnotself.user_consent['granted']:returnframe# Devolver cuadro sin procesarifself.consent_expired():self.user_consent=self.request_consent()returnself.detect_faces(frame)ifself.user_consent['granted']elseframe
Minimización de Datos
Implementa principios de minimización de datos:
Recopila solo lo necesario: Si solo necesitas detección facial para organizar fotos, no recojas información de identidad.
Minimiza almacenamiento: Procesa y elimina datos tan rápido como sea posible.
Almacenamiento seguro: Si los datos deben almacenarse, usa encriptación y controles de acceso.
Implementando estas recomendaciones desde el inicio, puedes crear sistemas de detección facial que respeten la privacidad del usuario, promuevan equidad y mantengan la confianza pública en tecnologías IA.
Recomendaciones Futuras
El panorama de soluciones para detección y tracking facial continúa evolucionando rápidamente. Aquí algunos trends clave a observar:
Optimización para edge sigue siendo un enfoque clave, con modelos volviéndose más eficientes manteniendo precisión
Prioridad de privacidad gana importancia, con más aplicaciones moviendo procesamiento al dispositivo en lugar de soluciones cloud
Reducción de sesgo se vuelve requisito estándar, con frameworks incluyendo pruebas de equidad
Herramientas de cumplimiento emergen para ayudar a desarrolladores cumplir con leyes de privacidad en evolución
Elegir Modelo
Elegir el modelo correcto de detección facial depende de balancear tus requisitos específicos. Comienza con estos criterios de decisión:
Para principiantes: Comienza con MediaPipe o YOLOv8-face por su excelente documentación y facilidad de uso
Para aplicaciones móviles: MediaPipe BlazeFace ofrece optimización móvil sin igual
Para aplicaciones críticas en precisión: RetinaFace proporciona rendimiento a nivel de investigación
Para despliegue edge: YOLOv10-face o EdgeFace ofrecen la mejor relación tamaño-rendimiento
Para tracking de video: ByteTrack proporciona consistencia de identidad superior entre cuadros
Para aplicaciones conscientes de privacidad: Prioriza modelos locales como MediaPipe o variantes ligeras de YOLO
Siempre prueba el rendimiento del modelo en tus datos específicos y entorno de despliegue. Las métricas en este artículo proporcionan un punto de partida, pero el rendimiento real puede variar dependiendo de calidad de imagen, condiciones de iluminación y especificaciones de hardware.