В этой статье сравниваем современные модели для детекции и трекинга лиц по ключевым критериям: скорости работы, точности распознавания и удобству развертывания. Разберем реальные примеры кода на Python, обсудим оптимизацию производительности и важные этические аспекты.
Распознавание лиц - ключевая технология, лежащая в основе множества решений: от разблокировки смартфонов до комплексных систем безопасности. Сегодня на рынке представлено десятки моделей, каждая из которых обещает высокую точность и скорость работы. Но как разобраться в этом многообразии и выбрать подходящую именно для твоего проекта?
Будь то мобильное приложение с распознаванием лиц в реальном времени или система видеонаблюдения с высокими требованиями к точности, правильный выбор модели критичен. Изучение сравнительных тестов и обзоров ведущих алгоритмов детекции и трекинга лиц - это первый шаг к эффективному внедрению технологии. Такой подход поможет не только сэкономить ресурсы, но и добиться стабильной и быстрой работы решения в реальных условиях.
Введение в технологии
Ландшафт производительности
Современные модели детекции лиц можно условно разделить на уровни производительности по соотношению скорости и точности. Комплексное тестирование показывает, что ведущие алгоритмы достигли впечатляющих результатов: они обеспечивают высокую скорость обработки без существенных потерь в точности.
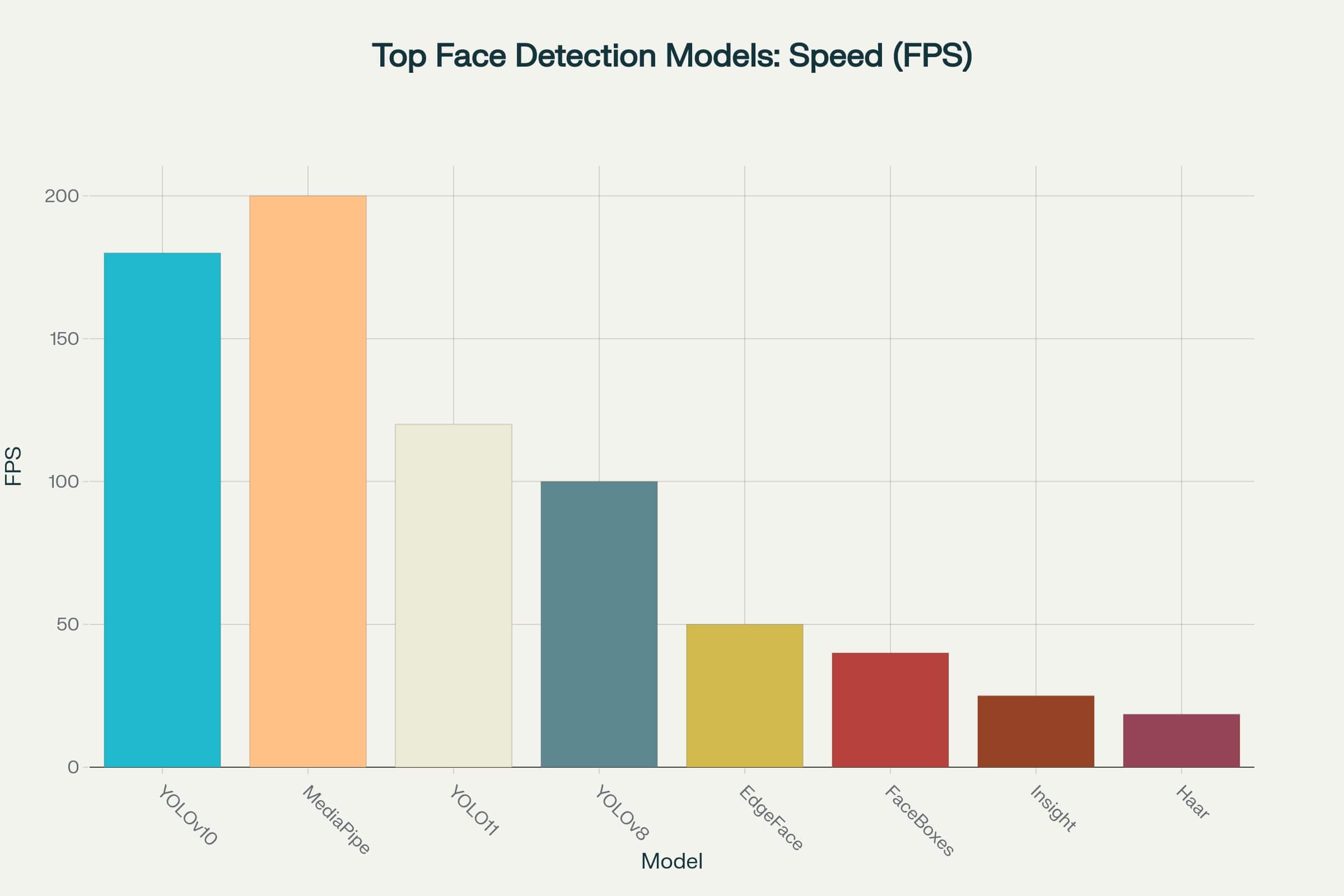
Это открывает возможности для их использования даже в приложениях с жесткими ограничениями по времени отклика - от мобильных устройств до edge-устройств в системах видеонаблюдения (кликни на изображение, чтобы открыть увеличенную версию).
График скорости топовых моделей детекции лиц
Если ориентироваться исключительно на скорость, MediaPipe и YOLOv10 выглядят безоговорочными фаворитами, обрабатывая от 180 до 200 кадров в секунду. Это делает их отличным выбором для задач в реальном времени, где важен минимальный отклик.
Однако высокая частота кадров - это ещё не всё. Без достаточной точности даже самая быстрая модель может оказаться неэффективной. Например, в системах видеонаблюдения или биометрической идентификации более медленные, но точные модели всё ещё имеют свои преимущества.
Компромиссы моделей
При анализе графика зависимости скорости (FPS - Frames Per Second) от точности (mAP - mean Average Precision) модели группируются в отчётливые кластеры, отражающие ключевые компромиссы в детекции лиц: повышение точности часто сопровождается снижением скорости, и наоборот.
График производительности топовых моделей детекции лиц
Эта диаграмма выявляет четыре отдельные категории моделей:
Только CPU (серые точки) - такие модели, как Haar Cascade и DLib HOG, обеспечивают базовую производительность без необходимости использования GPU. Они не отличаются высокой скоростью, но идеально подходят для устройств с ограниченными ресурсами и встроенных систем.
Лёгкие (голубые точки) - к ним относятся MediaPipe BlazeFace и различные версии YOLO. Эти модели предлагают отличную скорость обработки при разумном уровне точности, являясь оптимальным выбором для большинства приложений в реальном времени.
Средние (оранжевые точки) - модели вроде InsightFace SCRFD и EdgeFace обеспечивают повышенную точность при умеренной скорости работы. Их выбирают, когда важна точность, но при этом требуется сохранение достойной производительности.
Тяжеловесы (красные точки) - такие как RetinaFace и DSFD. Эти модели демонстрируют исследовательский уровень точности, но требуют значительных вычислительных ресурсов. Они предназначены для критически важных задач, где допустима высокая нагрузка на оборудование.
Практическая реализация
Ниже несколько примеров кода на Python для работы с разными моделями. Как видишь, все не так уж и сложно, базовые вещи достаточно просты:
Быстрый старт с YOLOv8-Face
YOLOv8 представляет отличный баланс между производительностью и простотой использования. Эта модель идеально подходит для начинающих разработчиков.
MediaPipe оптимизирован для мобильных платформ и обеспечивает стабильную производительность даже на устройствах среднего класса.
importmediapipeasmpimportcv2# Инициализируем MediaPipe Face Detection один разmp_face_detection=mp.solutions.face_detectionmp_drawing=mp.solutions.drawing_utilscap=cv2.VideoCapture(0)# Используем оператор 'with' вне цикла для правильного управления ресурсамиwithmp_face_detection.FaceDetection(model_selection=0,min_detection_confidence=0.5)asface_detection:whilecap.isOpened():success,image=cap.read()ifnotsuccess:print("Игнорируем пустой кадр с камеры.")continue# Для улучшения производительности, опционально помечаем изображение как нередактируемое# для передачи по ссылке.image.flags.writeable=Falseimage=cv2.cvtColor(image,cv2.COLOR_BGR2RGB)results=face_detection.process(image)# Рисуем аннотации детекции лиц на изображении.image.flags.writeable=Trueimage=cv2.cvtColor(image,cv2.COLOR_RGB2BGR)ifresults.detections:fordetectioninresults.detections:mp_drawing.draw_detection(image,detection)cv2.imshow('MediaPipe Face Detection',image)ifcv2.waitKey(5)&0xFF==27:# ESC keybreakcap.release()cv2.destroyAllWindows()
Продвинутая реализация с RetinaFace
Для задач, требующих максимальной точности, RetinaFace остается золотым стандартом в области детекции лиц.
Трекинг лиц (от англ. face tracking) - это процесс непрерывного отслеживания лиц в видео последовательности, который выходит далеко за рамки простого разового обнаружения. В отличие от детекции, трекинг требует устойчивой идентификации лиц на протяжении множества кадров, что предъявляет высокие требования к производительности алгоритмов.
На графике представлено сравнение популярных моделей трекинга по двум ключевым метрикам:
Скорость обработки (FPS) - количество кадров в секунду, определяющее быстродействие модели
MOTA (Multiple Object Tracking Accuracy) - это ключевая метрика для оценки качества трекинга объектов (включая лица), которая учитывает три основных типа ошибок:
False Positives (FP) - ложные срабатывания (трекер обнаружил несуществующий объект).
False Negatives (FN) - пропущенные объекты (трекер не нашел реально существующий объект).
ID Switches (IDs) - переключения идентификаторов (трекер “перепутал” метки объектов при их пересечении или временном исчезновении).
Формула расчета
$$
MOTA = 1 - \frac{\sum (FP + FN + IDs)}{\sum \text{Общее число объектов в каждом кадре}}
$$
Особенности
Диапазон значений: от $-\infty$ до 1 (чем ближе к 1, тем лучше).
Пример: MOTA = 0.85 означает, что трекер допустил ошибки в 15% случаев.
Интегральный показатель: объединяет все основные ошибки трекинга в одну оценку.
Критичен для задач видеонаблюдения, анализа поведения и автономных систем, где важна стабильность идентификации.
Отличие от других метрик
MOTP (Multiple Object Tracking Precision) - оценивает точность локализации объекта, но не учитывает ошибки идентификации.
IDF1 - фокусируется на корректности соответствия ID объектов между кадрами.
Для вашего графика высокая MOTA у модели (например, FairMOT или ByteTrack) указывает на ее надежность в сложных сценах (например, при перекрытии лиц или изменении освещения).
Среди представленных решений (Deeperport, FairMOT, ByteTrack и другие) наблюдается значительный разброс характеристик - некоторые модели демонстрируют высокую скорость в ущерб точности, тогда как другие обеспечивают точный трекинг, но работают медленнее.
Выбор оптимальной модели всегда зависит от конкретной задачи: для реального времени критична скорость (FPS), для аналитических систем - точность (MOTA). Особый интерес представляют гибридные подходы (например, FaceTracker difu), пытающиеся найти баланс между этими противоречивыми требованиями.
Сравнение топовых моделей детекции лиц
ByteTrack демонстрирует наилучший баланс скорости и точности: при рекордных 171 FPS он сохраняет высокий показатель MOTA. Это делает его оптимальным выбором для систем реального времени, где критичны и быстродействие, и стабильность идентификации объектов.
Реализация ByteTrack для видео
importcv2fromyolox.tracker.byte_trackerimportBYTETrackerfromultralyticsimportYOLOclassVideoTracker:def__init__(self):self.model=YOLO('yolov8n-face.pt')self.tracker=BYTETracker(frame_rate=30)deftrack_video(self,video_path):cap=cv2.VideoCapture(video_path)frame_id=0whileTrue:ret,frame=cap.read()ifnotret:break# Детекцияresults=self.model(frame)# Конвертируем в формат для отслеживанияdetections=[]iflen(results[0].boxes)>0:boxes=results[0].boxes.xyxy.cpu().numpy()scores=results[0].boxes.conf.cpu().numpy()forbox,scoreinzip(boxes,scores):detections.append([*box,score])# Обновляем трекерtracks=self.tracker.update(np.array(detections),frame.shape[:2],frame.shape[:2])# Рисуем трекиfortrackintracks:x1,y1,x2,y2,track_id=track[:5]cv2.rectangle(frame,(int(x1),int(y1)),(int(x2),int(y2)),(0,255,0),2)cv2.putText(frame,f'ID: {int(track_id)}',(int(x1),int(y1)-10),cv2.FONT_HERSHEY_SIMPLEX,0.6,(0,255,0),2)cv2.imshow('Face Tracking',frame)ifcv2.waitKey(1)&0xFF==ord('q'):breakframe_id+=1cap.release()cv2.destroyAllWindows()# Использованиеtracker=VideoTracker()tracker.track_video('path/to/video.mp4')
Для мобильных приложений с упором на плавный UX скорость распознавания лиц критически важна - здесь оптимальны модели с 30-60+ FPS, работающие даже на слабых устройствах.
Почему это важно?
Без лагов: 60 FPS = обработка каждого кадра за 16 мс (частота обновления экрана смартфонов).
Энергоэффективность: Малые модели (например, MobileFaceNet) экономят заряд.
Оффлайн-работа: Локальное выполнение без задержек на сервер.
Аппаратная оптимизация: Использование NPU/GPU телефона (например, CoreML на iOS, NNAPI на Android).
Кэширование: Предсказуемые сценарии (например, повторное распознавание того же лица) ускоряют работу.
Пример: Snapchat фильтры работают в реальном времени именно благодаря таким оптимизациям. Так что выбор модели с хорошим балансом скорость/точность является одним из ключевых факторов успеха мобильного приложения.
# Реализация детектора лиц для мобильных устройств.importmediapipeasmpimportcv2importnumpyasnpimporttimeclassMobileFaceDetector:"""
Класс для детекции лиц в видеопотоке, оптимизированный для
производительности на мобильных устройствах.
Включает в себя пропуск кадров для достижения целевого FPS и плавную
отрисовку рамок, чтобы избежать "мерцания".
"""def__init__(self,model_selection=0,min_detection_confidence=0.7):"""
Инициализирует детектор лиц.
Args:
model_selection (int): Выбор модели. 0 для ближнего радиуса (до 2 метров),
1 для дальнего (до 5 метров).
min_detection_confidence (float): Минимальный порог уверенности для детекции.
"""# --- Инициализация MediaPipe Face Detection ---# Создаем экземпляр с заданными параметрами.self.face_detection=mp.solutions.face_detection.FaceDetection(model_selection=model_selection,min_detection_confidence=min_detection_confidence,)# --- Переменные для отрисовки и FPS ---# Храним последние успешные детекции, чтобы рисовать их на пропущенных кадрах.self.last_results=None# Сохраняем исходные размеры кадра для корректного масштабирования.self.original_width=0self.original_height=0def_draw_detections(self,frame,detections):"""
Вспомогательная функция для отрисовки рамок на кадре.
Args:
frame (np.ndarray): Кадр, на котором нужно рисовать.
detections: Результаты детекции от MediaPipe.
"""ifdetections:fordetectionindetections:# Получаем относительные координаты рамки (от 0.0 до 1.0).bboxC=detection.location_data.relative_bounding_box# Масштабируем координаты обратно к исходному размеру кадра.x=int(bboxC.xmin*self.original_width)y=int(bboxC.ymin*self.original_height)width=int(bboxC.width*self.original_width)height=int(bboxC.height*self.original_height)# Рисуем прямоугольник на оригинальном кадре.cv2.rectangle(frame,(x,y),(x+width,y+height),(0,255,0),2)returnframedefprocess_frame(self,frame,target_width=320):"""
Обрабатывает один кадр из видеопотока.
Args:
frame (np.ndarray): Входной кадр в формате BGR.
target_width (int): Целевая ширина для обработки. Кадр будет
пропорционально уменьшен до этой ширины.
Returns:
np.ndarray: Кадр с нарисованными рамками.
"""self.original_height,self.original_width=frame.shape[:2]# --- Оптимизация 1: Уменьшение разрешения ---# Сохраняем соотношение сторон.scale=target_width/self.original_widthsmall_frame=cv2.resize(frame,(0,0),fx=scale,fy=scale,interpolation=cv2.INTER_AREA)# --- Оптимизация 2: Конвертация цвета и повышение производительности ---# MediaPipe требует RGB. Конвертируем один раз.rgb_small_frame=cv2.cvtColor(small_frame,cv2.COLOR_BGR2RGB)# Помечаем кадр как "только для чтения" для ускорения.rgb_small_frame.flags.writeable=False# --- Детекция лиц ---results=self.face_detection.process(rgb_small_frame)# Восстанавливаем флаг, если нужно будет еще работать с кадром.rgb_small_frame.flags.writeable=True# --- Отрисовка ---# Если детекция была успешной, сохраняем результаты.ifresults.detections:self.last_results=results.detections# Рисуем рамки на исходном кадре. Если в текущем кадре лиц не найдено,# но они были в предыдущих, используем старые данные для плавности.processed_frame=self._draw_detections(frame,self.last_results)returnprocessed_framedefclose(self):"""Освобождает ресурсы MediaPipe."""self.face_detection.close()# --- Пример использования с веб-камерой ---if__name__=='__main__':# Инициализируем детекторdetector=MobileFaceDetector(min_detection_confidence=0.5)# Захватываем видео с веб-камеры (0 - обычно встроенная камера)cap=cv2.VideoCapture(0)ifnotcap.isOpened():print("Ошибка: не удалось открыть веб-камеру.")exit()# Переменные для расчета FPSprev_frame_time=0new_frame_time=0try:whileTrue:# Читаем кадр с камерыsuccess,frame=cap.read()ifnotsuccess:print("Не удалось получить кадр. Завершение работы.")break# Переворачиваем кадр для эффекта "зеркала"frame=cv2.flip(frame,1)# --- Пропускаем обработку для достижения целевого FPS ---# Это менее важно с новой логикой отрисовки, но все еще экономит ресурсы# Здесь можно реализовать вашу логику пропуска кадров, если требуется# Обрабатываем кадрprocessed_frame=detector.process_frame(frame)# --- Расчет и отображение FPS ---new_frame_time=time.time()fps=1/(new_frame_time-prev_frame_time)prev_frame_time=new_frame_timecv2.putText(processed_frame,f'FPS: {int(fps)}',(10,30),cv2.FONT_HERSHEY_SIMPLEX,1,(0,255,0),2)# Показываем результатcv2.imshow('Mobile Face Detection',processed_frame)# Выход по нажатию клавиши 'q'ifcv2.waitKey(1)&0xFF==ord('q'):breakfinally:# Освобождаем ресурсыprint("Освобождение ресурсов...")cap.release()detector.close()cv2.destroyAllWindows()
Рекомендуемый стек:
Для детекции:
MediaPipe Face Detection (BlazeFace) - оптимален для мобилок
Для трекинга:
MediaPipe Face Mesh (468 точек) - если нужны landmarks
Lightweight OpenPose - для упрощенного трекинга
Производительность:
60-100 FPS на среднестатистическом смартфоне (Snapdragon 7xx)
До 200 FPS на флагманах (Snapdragon 8 Gen 2/Apple A15+)
Память:
Минимум 2ГБ RAM для базового функционала
3-4ГБ+ для сложных сценариев (одновременная детекция+трекинг)
Оптимизация:
Использование TFLite с аппаратным ускорением (GPU/NPU)
Кэширование результатов для статичных сцен
Динамическое понижение качества при перегреве устройства
Системы безопасности
Приложения безопасности требуют максимальной точности с приемлемой задержкой:
# Система безопасности с трекингом, верификацией,# оптимизированным распознаванием и визуализацией.importcv2importnumpyasnpimporttimeimportosimportpicklefromtypingimportDict,List,Any,Optional,Tuple# --- Предполагается, что эти библиотеки установлены ---# pip install opencv-python numpy# pip install insightface# pip install retinaface-pytorch deep-sort-realtime## Важно: InsightFace требует onnxruntime-gpu. DeepSort также имеет свои зависимости.# Установка может потребовать дополнительных шагов, включая загрузку моделей.fromretinafaceimportRetinaFacefromdeep_sort_realtime.deepsort_trackerimportDeepSortfrominsightface.appimportFaceAnalysisclassAdvancedSecuritySystem:"""
Комплексная система безопасности, объединяющая детекцию, трекинг и
распознавание лиц с оптимизациями для реального времени.
"""def__init__(self,db_path:str,detection_thresh:float=0.9,recognition_thresh:float=0.5):"""
Инициализация всех компонентов системы.
Args:
db_path (str): Путь к файлу базы данных лиц (.pkl).
detection_thresh (float): Порог уверенности для детектора лиц.
recognition_thresh (float): Порог сходства для распознавания лиц.
"""print("Инициализация системы безопасности...")# --- Детектор лиц (RetinaFace) ---# RetinaFace хорошо подходит для обнаружения "сложных" лиц.# Для CPU можно использовать 'mobilenet', для GPU - 'resnet50'.self.detector=RetinaFace(gpu_id=0)# Укажите -1 для использования CPUprint("Детектор лиц (RetinaFace) инициализирован.")# --- Трекер (DeepSort) ---# max_age: сколько кадров трек может существовать без детекции.# n_init: сколько раз объект должен быть детектирован для старта трекинга.self.tracker=DeepSort(max_age=30,n_init=3)print("Трекер (DeepSort) инициализирован.")# --- Распознаватель лиц (InsightFace) ---# Используем CUDA для максимальной производительности.self.recognizer=FaceAnalysis(name='buffalo_l',providers=['CUDAExecutionProvider'])self.recognizer.prepare(ctx_id=0)# ctx_id=0 для GPU, -1 для CPUprint("Распознаватель лиц (InsightFace) инициализирован.")# --- Параметры и база данных ---self.detection_thresh=detection_threshself.recognition_thresh=recognition_threshself.face_db=self._load_face_database(db_path)# Словарь для хранения уже распознанных личностей по track_id# {track_id: {"identity": "Name", "verified": True/False}}self.tracked_identities:Dict[str,Dict[str,Any]]={}def_load_face_database(self,db_path:str)->Optional[Dict[str,np.ndarray]]:"""Загружает предварительно созданную базу данных эмбеддингов."""ifnotos.path.exists(db_path):print(f"Ошибка: Файл базы данных не найден по пути: {db_path}")print("Пожалуйста, сначала создайте базу данных с помощью create_database_from_folder().")returnNonewithopen(db_path,'rb')asf:db=pickle.load(f)print(f"База данных лиц успешно загружена. Найдено {len(db)} личностей.")returndbdef_extract_embedding(self,frame:np.ndarray,bbox:np.ndarray)->Optional[np.ndarray]:"""Извлекает эмбеддинг (вектор признаков) из области лица."""# Безопасно вырезаем лицо, обрезая координаты по границам кадраh,w=frame.shape[:2]x1,y1,x2,y2=np.maximum(0,bbox).astype(int)x2,y2=min(x2,w),min(y2,h)face_img=frame[y1:y2,x1:x2]ifface_img.size==0:returnNone# Используем InsightFace для получения эмбеддингаfaces=self.recognizer.get(face_img)returnfaces[0].embeddingiffaceselseNonedef_find_match(self,embedding:np.ndarray)->Tuple[str,float]:"""Находит наиболее похожее лицо в базе данных."""ifembeddingisNoneorself.face_dbisNone:return"Unknown",0.0best_match="Unknown"best_score=0.0# Используем косинусное сходство (скалярное произведение нормализованных векторов)forname,db_embedinself.face_db.items():score=np.dot(embedding,db_embed)/(np.linalg.norm(embedding)*np.linalg.norm(db_embed))ifscore>self.recognition_threshandscore>best_score:best_score=scorebest_match=namereturnbest_match,best_scoredefprocess_frame(self,frame:np.ndarray)->np.ndarray:"""
Полный цикл обработки одного кадра: детекция, трекинг, распознавание.
Returns:
np.ndarray: Кадр с нарисованной информацией (рамки, ID, имена).
"""ifself.face_dbisNone:cv2.putText(frame,"Face DB not loaded!",(20,40),cv2.FONT_HERSHEY_SIMPLEX,1,(0,0,255),2)returnframe# --- 1. Детекция ---# RetinaFace возвращает словарь, который нужно преобразоватьdetections_raw=self.detector.detect(frame,threshold=self.detection_thresh)# Конвертация в формат, понятный для DeepSort: [[x1, y1, x2, y2], confidence]deepsort_detections=[]forface_dataindetections_raw:x1,y1,x2,y2,conf=face_datadeepsort_detections.append(([x1,y1,x2,y2],conf,"face"))# --- 2. Трекинг ---tracks=self.tracker.update_tracks(deepsort_detections,frame=frame)# --- 3. Распознавание и Визуализация ---fortrackintracks:ifnottrack.is_confirmed():continuetrack_id=track.track_idbbox=track.to_tlbr()# (x1, y1, x2, y2)identity_info=self.tracked_identities.get(track_id)# ОПТИМИЗАЦИЯ: Распознаем только новые трекиifidentity_infoisNone:embedding=self._extract_embedding(frame,bbox)name,score=self._find_match(embedding)self.tracked_identities[track_id]={"identity":name,"score":score}identity_info=self.tracked_identities[track_id]# --- Визуализация ---name=identity_info.get("identity","Unknown")score=identity_info.get("score",0.0)color=(0,255,0)ifname!="Unknown"else(0,0,255)# Рисуем рамкуcv2.rectangle(frame,(int(bbox[0]),int(bbox[1])),(int(bbox[2]),int(bbox[3])),color,2)# Формируем текст для подписиlabel=f"ID: {track_id} | {name} ({score:.2f})"# Рисуем подписьcv2.putText(frame,label,(int(bbox[0]),int(bbox[1])-10),cv2.FONT_HERSHEY_SIMPLEX,0.7,color,2)returnframedefcreate_database_from_folder(self,folder_path:str,output_db_path:str):"""
Создает базу данных эмбеддингов из папки с изображениями.
Структура папки:
- folder_path/
- person_1/
- image1.jpg
- image2.png
- person_2/
- photo.jpg
"""face_db={}print(f"Создание базы данных из папки: {folder_path}")forperson_nameinos.listdir(folder_path):person_folder=os.path.join(folder_path,person_name)ifnotos.path.isdir(person_folder):continueembeddings=[]forimage_nameinos.listdir(person_folder):image_path=os.path.join(person_folder,image_name)img=cv2.imread(image_path)ifimgisNone:continue# Получаем эмбеддинг для первого найденного лица на фотоfaces=self.recognizer.get(img)iffaces:embeddings.append(faces[0].embedding)ifembeddings:# Усредняем эмбеддинги для большей устойчивостиface_db[person_name]=np.mean(embeddings,axis=0)print(f"-> Найдено и обработано лицо: {person_name}")# Сохраняем базу в файлwithopen(output_db_path,'wb')asf:pickle.dump(face_db,f)print(f"База данных успешно создана и сохранена в: {output_db_path}")# --- Пример использования ---if__name__=='__main__':DB_FILE="face_db.pkl"DB_SOURCE_FOLDER="face_images"# Папка с фото для создания БД# --- Шаг 1: Создание базы данных (выполняется один раз) ---# Для этого шага нужно создать папку face_images и в ней подпапки с именами# людей, содержащие их фотографии.ifnotos.path.exists(DB_FILE):print("База данных не найдена. Запуск процесса создания...")# Создаем временную папку для примера, если ее нетifnotos.path.exists(DB_SOURCE_FOLDER):os.makedirs(os.path.join(DB_SOURCE_FOLDER,"person_example"))print(f"Создана папка для примера: {DB_SOURCE_FOLDER}/person_example")print("Пожалуйста, поместите туда файлы .jpg с лицами и перезапустите скрипт.")exit()# Инициализируем систему только для создания БДtemp_system=AdvancedSecuritySystem(db_path=DB_FILE)temp_system.create_database_from_folder(DB_SOURCE_FOLDER,DB_FILE)print("-"*30)# --- Шаг 2: Запуск системы на видеопотоке ---system=AdvancedSecuritySystem(db_path=DB_FILE)cap=cv2.VideoCapture(0)# 0 для веб-камеры или путь к видеофайлуifnotcap.isOpened():print("Ошибка: не удалось открыть видеопоток.")exit()prev_time=0try:whileTrue:success,frame=cap.read()ifnotsuccess:break# Обработка кадраprocessed_frame=system.process_frame(frame)# Расчет и отображение FPScurr_time=time.time()fps=1/(curr_time-prev_time)prev_time=curr_timecv2.putText(processed_frame,f"FPS: {int(fps)}",(20,80),cv2.FONT_HERSHEY_SIMPLEX,1,(0,255,0),2)cv2.imshow("Advanced Security System",processed_frame)ifcv2.waitKey(1)&0xFF==ord('q'):breakfinally:print("Завершение работы и освобождение ресурсов.")cap.release()cv2.destroyAllWindows()
Рекомендуемый стек:
Для детекции:
RetinaFace (ResNet50) - максимальная точность для критических задач
SCRFD - оптимизированная версия для edge-устройств
Для трекинга:
DeepSORT - лучшая стабильность при окклюзиях
ByteTrack - максимальная производительность (до 50 FPS)
Асинхронная pipeline-обработка для распределенных систем
Безопасность:
Обязательная liveness-проверка (антиспуфинг)
Шифрование эмбеддингов в базе данных
Временные метки для аудита доступа
Edge и IoT
Среды с ограниченными ресурсами требуют тщательной оптимизации:
# Реализация детекции и трекинга лиц для Edge-устройств# с использованием TensorFlow Lite.importcv2importnumpyasnpimporttimeimportargparsefromtypingimportList,Dict,Any,Tuple,Optional# Для работы этого скрипта требуется tflite_runtime.# Установка: pip install tflite-runtimetry:fromtflite_runtime.interpreterimportInterpreterexceptImportError:print("Ошибка: tflite_runtime не найден. Пожалуйста, установите его:")print("pip install tflite-runtime")exit()classEdgeFacePipeline:"""
Класс для детекции и трекинга лиц на Edge-устройствах с использованием TFLite.
Включает аппаратные оптимизации и легковесный IOU-трекер.
"""def__init__(self,model_path:str,device:str='cpu',conf_thresh:float=0.7):"""
Инициализация пайплайна.
Args:
model_path (str): Путь к файлу модели .tflite.
device (str): Устройство для выполнения ('cpu' или 'npu').
conf_thresh (float): Порог уверенности для детекции лиц.
"""print(f"Загрузка TFLite модели из: {model_path}")self.interpreter=Interpreter(model_path=model_path)self.interpreter.allocate_tensors()self.input_details=self.interpreter.get_input_details()self.output_details=self.interpreter.get_output_details()# Важно: получаем точные размеры, которые требует модельself.input_height=self.input_details[0]['shape'][1]self.input_width=self.input_details[0]['shape'][2]self.conf_thresh=conf_threshself.tracked_faces:List[Dict[str,Any]]=[]self.next_track_id=0self.iou_thresh=0.4# Порог IOU для трекингаself._configure_device(device)print(f"Пайплайн инициализирован для устройства: {device}")def_configure_device(self,device:str):"""Применяет аппаратно-специфичные оптимизации."""cv2.setUseOptimized(True)# Настройки для нейропроцессора (NPU)ifdevice=='npu':# Здесь могут быть специфичные делегаты для NPU, например, 'libedgetpu.so.1'# self.interpreter = Interpreter(model_path=self.model_path,# experimental_delegates=[load_delegate('libedgetpu.so.1')])self.interpreter.set_num_threads(1)print("Оптимизации для NPU применены (упрощенная конфигурация).")# Оптимизации для CPUelse:self.interpreter.set_num_threads(4)print("Оптимизации для CPU применены (4 потока).")def_preprocess(self,frame:np.ndarray)->np.ndarray:"""
Подготовка кадра для нейросети: изменение размера и нормализация.
"""# Ресайз к точному размеру входа модели ---resized_frame=cv2.resize(frame,(self.input_width,self.input_height))# Преобразование в RGB, если модель этого требуетrgb_frame=cv2.cvtColor(resized_frame,cv2.COLOR_BGR2RGB)# Нормализация и добавление batch-измерения# Многие модели TFLite ожидают float32 в диапазоне [-1, 1] или [0, 1]# или uint8 [0, 255]. Проверяйте документацию к вашей модели.# Здесь мы предполагаем float32 [0, 1].input_data=np.expand_dims(rgb_frame,axis=0).astype(np.float32)/255.0returninput_datadefprocess_frame(self,frame:np.ndarray)->List[Dict[str,Any]]:"""
Полный цикл обработки: детекция и трекинг.
Args:
frame (np.ndarray): Входной кадр в формате BGR.
Returns:
List[Dict[str, Any]]: Список отслеживаемых лиц с их ID и координатами.
"""original_h,original_w=frame.shape[:2]# 1. Предобработка кадраinput_data=self._preprocess(frame)# 2. Инференс моделиself.interpreter.set_tensor(self.input_details[0]['index'],input_data)self.interpreter.invoke()# 3. Получение и постобработка результатов# Формат выхода может отличаться для разных моделей.# Предполагаем, что модель возвращает [boxes, scores].boxes=self.interpreter.get_tensor(self.output_details[0]['index'])[0]scores=self.interpreter.get_tensor(self.output_details[1]['index'])[0]current_detections=[]fori,scoreinenumerate(scores):ifscore>self.conf_thresh:# Координаты возвращаются в нормализованном виде [ymin, xmin, ymax, xmax]ymin,xmin,ymax,xmax=boxes[i]# Масштабирование координат к исходному размеру кадраabs_xmin=int(xmin*original_w)abs_ymin=int(ymin*original_h)abs_xmax=int(xmax*original_w)abs_ymax=int(ymax*original_h)current_detections.append({'bbox':(abs_xmin,abs_ymin,abs_xmax,abs_ymax),'score':float(score)})# 4. Обновление трекераself._update_tracker(current_detections)returnself.tracked_facesdef_update_tracker(self,new_detections:List[Dict[str,Any]]):"""Обновляет треки на основе новых детекций, используя IOU."""ifnotself.tracked_faces:# Если треков нет, инициализируем их из новых детекцийfordetinnew_detections:det['track_id']=self.next_track_iddet['age']=0# Счётчик "возраста" трекаself.tracked_faces.append(det)self.next_track_id+=1returnmatched_indices=set()# Попытка сопоставить новые детекции с существующими трекамиfori,trackinenumerate(self.tracked_faces):best_match_iou=0best_match_idx=-1forj,detinenumerate(new_detections):ifjinmatched_indices:continueiou=self._calculate_iou(track['bbox'],det['bbox'])ifiou>self.iou_threshandiou>best_match_iou:best_match_iou=ioubest_match_idx=jifbest_match_idx!=-1:# Обновляем трекtrack['bbox']=new_detections[best_match_idx]['bbox']track['age']=0# Сбрасываем возраст, т.к. трек найденmatched_indices.add(best_match_idx)else:# Увеличиваем возраст, если трек не найденtrack['age']+=1# Добавляем новые треки для не сопоставленных детекцийforj,detinenumerate(new_detections):ifjnotinmatched_indices:det['track_id']=self.next_track_iddet['age']=0self.tracked_faces.append(det)self.next_track_id+=1# Удаляем старые треки, которые не были видны некоторое времяself.tracked_faces=[tfortinself.tracked_facesift['age']<15]@staticmethoddef_calculate_iou(box1:Tuple,box2:Tuple)->float:"""Вычисляет Intersection over Union (IOU) для двух рамок."""x1,y1,x2,y2=box1x3,y3,x4,y4=box2xi1,yi1=max(x1,x3),max(y1,y3)xi2,yi2=min(x2,x4),min(y2,y4)inter_area=max(0,xi2-xi1)*max(0,yi2-yi1)box1_area=(x2-x1)*(y2-y1)box2_area=(x4-x3)*(y4-y3)union_area=box1_area+box2_area-inter_areareturninter_area/union_areaifunion_area>0else0.0defdraw_results(frame:np.ndarray,faces:List[Dict[str,Any]]):"""Отрисовывает результаты на кадре."""forfaceinfaces:# Используем координаты для отрисовкиxmin,ymin,xmax,ymax=face['bbox']track_id=face['track_id']cv2.rectangle(frame,(xmin,ymin),(xmax,ymax),(0,255,0),2)label=f"ID: {track_id}"cv2.putText(frame,label,(xmin,ymin-10),cv2.FONT_HERSHEY_SIMPLEX,0.7,(0,255,0),2)# Пример использованияif__name__=="__main__":parser=argparse.ArgumentParser(description="Face Detection on Edge Devices")parser.add_argument("--model",type=str,required=True,help="Path to the .tflite model file.")parser.add_argument("--device",type=str,default='cpu',choices=['cpu','npu'],help="Device to run inference on.")parser.add_argument("--video",type=str,help="Path to video file. If not provided, uses webcam.")args=parser.parse_args()pipeline=EdgeFacePipeline(model_path=args.model,device=args.device)cap=cv2.VideoCapture(args.videoifargs.videoelse0)ifnotcap.isOpened():print(f"Ошибка: не удалось открыть видеоисточник.")exit()prev_time=0try:whileTrue:ret,frame=cap.read()ifnotret:break# Обработка кадраtracked_faces=pipeline.process_frame(frame)# Визуализация результатовdraw_results(frame,tracked_faces)# Отображение FPScurr_time=time.time()fps=1/(curr_time-prev_time)prev_time=curr_timecv2.putText(frame,f"FPS: {int(fps)}",(10,30),cv2.FONT_HERSHEY_SIMPLEX,1,(0,0,255),2)cv2.imshow('Edge Face Detection',frame)ifcv2.waitKey(1)&0xFF==ord('q'):breakfinally:print("Завершение работы и освобождение ресурсов.")cap.release()cv2.destroyAllWindows()
Рекомендуемый стек:
Для детекции:
YOLOv10n-face (Nano версия) – до 180 FPS на Raspberry Pi
Haar Cascades – минимальные требования (работает даже на ESP32)
MobileNetV3-SSD – баланс точности и скорости (30–60 FPS)
Для трекинга:
IOU Tracker – ультра-лёгкий трекинг (0.1 мс на кадр)
CSRT – точный трекинг для статичных камер
KCF – компромисс между скоростью и точностью
Производительность:
30–180 FPS в зависимости от железа и модели
1–5 Вт энергопотребления
Память:
Минимум 512 МБ RAM для Haar Cascades
1–2 ГБ RAM для YOLOv10n и MobileNet
Оптимизация:
TensorFlow Lite для деплоя
Квантование в INT8 для ускорения
Аппаратное ускорение (NPU, GPU)
Динамическое масштабирование разрешения
Поддерживаемые устройства:
Raspberry Pi (3B+/4/5)
Jetson Nano
Orange Pi 5
ESP32-CAM (только Haar Cascades)
Установка и настройка
Настройка окружения
Правильная настройка среды разработки критична для достижения оптимальной производительности.
Эффективное управление памятью и вычислительными ресурсами существенно влияет на производительность системы.
importgcimporttorchdefoptimize_gpu_memory():"""Очистка GPU памяти после обработки"""iftorch.cuda.is_available():torch.cuda.empty_cache()gc.collect()defbatch_processing(image_list,model,batch_size=4):"""Пакетная обработка для оптимизации пропускной способности"""results=[]foriinrange(0,len(image_list),batch_size):batch=image_list[i:i+batch_size]batch_results=model(batch)results.extend(batch_results)# Очистка памяти после каждого батчаoptimize_gpu_memory()returnresults
Многопоточная обработка
Разделение процессов чтения, обработки и отображения кадров позволяет максимально использовать доступные ресурсы системы.
Модели детекции лиц могут проявлять различия в производительности среди разных демографических групп. Многие модели работают менее точно (погрешность может быть на 30% больше) при детекции и трекинге лиц людей с более темным тоном кожи, женщин и пожилых людей.
Несколько советов, чтобы избежать таких ситуаций:
Тестируй на разных демографических группах: Всегда оценивай производительность выбранной модели для разных возрастных групп, полов и этносов, используя разнообразные тестовые наборы данных.
Использование дебайазинговых моделей (напр. DebFace)
Мониторь производительность в реальном мире: Непрерывно оценивай, как твоя система работает для разных групп пользователей в продакшн средах.
Рассматривай специализированные модели: Некоторые фреймворки, такие как MediaPipe и новые варианты YOLO, были специально обучены на более разнообразных наборах данных для снижения предвзятости.
# Пример: фреймворк тестирования предвзятостиdefevaluate_model_bias(model,test_datasets):"""
Оценка производительности модели по демографическим группам
"""results={}forgroup_name,datasetintest_datasets.items():detections=[]forimage_pathindataset['images']:result=model(image_path)detections.append(result)# Вычисляем метрики для этой демографической группыaccuracy=calculate_accuracy(detections,dataset['ground_truth'])results[group_name]={'accuracy':accuracy,'sample_size':len(dataset['images'])}returnresults# Пример использованияdemographic_results=evaluate_model_bias(model,{'young':young_adult_dataset,'elderly':elderly_dataset,'diverse':diverse_dataset})
Примечание: фрагменты кода в этом разделе представляют концептуальные фреймворки. Вспомогательные функции, такие как calculate_accuracy, present_consent_dialog, или конкретные UI реализации, должны быть разработаны на основе требований твоего приложения и выбранных фреймворков.
Приоритет приватности
Выбор между обработкой данных локально или в облаке может иметь значительные последствия для приватности:
Преимущества локальной обработки:
Персональные данные не покидают устройство пользователя
Снижается риск утечек данных
Соответствие требованиям, таким как GDPR
Пользователь сохраняет контроль над своими биометрическими данными
Получение согласия
Технологии отслеживания лиц также поднимают важные вопросы о согласии и прозрачности:
Лучшие практики для согласия:
Пользователи должны понимать, какие данные собираются и как они используются
Предоставляй опции отказа от трекинга, сохраняя основную функциональность
Периодически проси пользователей подтвердить их согласие
Пример реализации:
classConsentAwareFaceTracker:def__init__(self):self.user_consent=self.check_user_consent()self.tracking_enabled=Falsedefcheck_user_consent(self):# Проверяем сохраненные пользовательские предпочтения# Возвращаем статус согласия и временную меткуpassdefrequest_consent(self):"""
Представляем четкий диалог согласия пользователю
"""consent_text="""
Это приложение использует детекцию лиц для:
- Улучшения твоего опыта с AR фильтрами
- Автоматической фокусировки камеры на лицах
Твои данные лица:
- Обрабатываются полностью на твоем устройстве
- Никогда не сохраняются и не передаются
- Могут быть отключены в любое время в настройках
Согласен ли ты на детекцию лиц? [Да/Нет]
"""returnself.present_consent_dialog(consent_text)defprocess_with_consent(self,frame):ifnotself.user_consent['granted']:returnframe# Возвращаем необработанный кадрifself.consent_expired():self.user_consent=self.request_consent()returnself.detect_faces(frame)ifself.user_consent['granted']elseframe
Минимизация данных
Реализуй принципы минимизации данных:
Собирай только необходимое: Если тебе нужна только детекция лиц для организации фото, не собирай информацию об идентичности.
Минимизируй хранение: Обрабатывай и удаляй данные как можно быстрее.
Безопасное хранение: Если данные должны храниться, используй шифрование и контроль доступа.
Реализуя эти рекомендации с самого начала, мы можешь создавать системы детекции лиц, которые уважают приватность пользователей, продвигают справедливость и поддерживают общественное доверие к ИИ технологиям.
Рекомендации на будущее
Ландшафт решений для детекции и трекинга лиц продолжает быстро развиваться. Вот несколько ключевых трендов, на которые стоит обратить внимание:
Оптимизация для edge остается ключевым фокусом, с моделями, становящимися все более эффективными, сохраняя точность
Приоритет приватности набирает важность, с большим количеством приложений, переносящих обработку на устройство, а не облачные решения
Снижение предвзятости становится стандартным требованием, с фреймворками, включающими тестирование справедливости
Соответствие требованиям появляются, чтобы помочь разработчикам соответствовать развивающимся законам о приватности
Выбор модели для проекта
Выбор правильной модели детекции лиц зависит от балансирования твоих конкретных требований. Начни с этих критериев принятия решений:
Для новичков: Начни с MediaPipe или YOLOv8-face за их отличную документацию и простоту использования
Для мобильных приложений: MediaPipe BlazeFace предлагает непревзойденную мобильную оптимизацию
Для критически важных по точности приложений: RetinaFace обеспечивает производительность исследовательского уровня
Для edge развертывания: YOLOv10-face или EdgeFace предлагают лучшее соотношение размер-производительность
Для отслеживания видео: ByteTrack обеспечивает превосходную постоянность идентичности между кадрами
Для приложений, заботящихся о приватности: Приоритет локальным моделям, таким как MediaPipe или легковесным вариантам YOLO
Проверяй производительность работы моделей на твоих конкретных данных и в твоей среде развертывания. Метрики в этой статье предоставляют собой лишь отправную точку, а реальная производительность может варьироваться в зависимости от качества изображения, условий освещения и спецификаций железа.